Beautiful Soupを使ってAmazonの商品情報をスクレイピングする方法
ウェブスクレイピングは、ウェブサイトから関連する情報を抽出し、ローカルシステムに保存してさらなる利用に供するためのプログラミング技術です。
現代において、ウェブスクレイピングはデータサイエンスとマーケティングの分野で多くの応用があります。世界中のウェブスクレイパーが、個人や職業に関係なく多くの情報を集めます。さらに、現代のテック企業は、消費者のニーズを満たすためにこのようなウェブスクレイピング手法に頼っています。
この記事では、Amazonのウェブサイトから商品情報を収集します。したがって、対象商品として「プレイステーション4」を考慮に入れます。
注意:ウェブサイトのレイアウトやタグは時間の経過とともに変わる場合があります。そのため、読者はスクレイピングの概念を理解しておくことをお勧めします。自己実装が問題にならないようにご注意ください。
ウェブスクレイピングサービス
ウェブスクレイピングを使ったサービスを構築したい場合、IPブロッキングやプロキシの管理にも対応する必要があるかもしれません。基盤となる技術やプロセスを知っていることは良いことですが、大量のスクレイピングを行う場合は、ZenscrapeのようなスクレイピングAPIプロバイダーと一緒に作業する方が良いです。彼らはAjaxリクエストや動的ページのためのJavaScriptも手配してくれます。彼らの人気のあるオファリングの一つはレジデンシャルプロキシサービスです。
いくつかの基本的な要件:
スープを作るためには適切な材料が必要です。同様に、新鮮なウェブスクレイパーには特定のコンポーネントが必要です。
- Python – The ease of use and a vast collection of libraries make Python the numero-uno for scraping websites. However, if the user does not have it pre-installed, refer here.
- Beautiful Soup – One of the many Web Scraping libraries for Python. The easy and clean usage of the library makes it a top contender for web scraping. After a successful installation of Python, user can install Beautiful Soup by:
pip install bs4
- Basic Understanding of HTML Tags – Refer to this tutorial for gaining necessary information about HTML tags.
- Web Browser – Since we have to toss out a lot of unnecessary information from a website, we need specific ids and tags for filtering. Therefore, a web browser like Google Chrome or Mozilla Firefox serves the purpose of discovering those tags.
ユーザーエージェントの作成
多くのウェブサイトは、データへのアクセスを禁止するための特定のプロトコルを持っています。したがって、スクリプトからデータを抽出するためには、ユーザーエージェントを作成する必要があります。ユーザーエージェントは、要求を送信するホストの種類についてサーバーに伝える文字列です。
このウェブサイトには、ユーザーエージェントをたくさん選ぶことができるように掲載されています。以下はヘッダー内のユーザーエージェントの例です。
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
必要な場合、HEADERSには「Accept-Language」という追加のフィールドがあり、ウェブページを英語(アメリカ)に翻訳します。
URLにリクエストを送信する
URL(統一資源位置識別子)によってウェブページにアクセスします。URLのおかげで、データにアクセスするためにウェブページにリクエストを送信します。
URL = "https://www.amazon.com/Sony-PlayStation-Pro-1TB-Console-4/dp/B07K14XKZH/"
webpage = requests.get(URL, headers=HEADERS)
要求されたウェブページにはAmazonの商品が掲載されています。そのため、私たちのPythonスクリプトは、「商品名」「現在の価格」などの商品の詳細情報を抽出することに焦点を当てています。
注意:URLへのリクエストは「requests」ライブラリを使用して送信されます。ユーザーが「No module named requests」エラーを受け取った場合は、「pip install requests」でインストールすることができます。
情報のスープを作り出す
ウェブページの変数には、ウェブサイトから受け取った応答が含まれています。私たちは、応答の内容とパーサーのタイプをBeautiful Soupの関数に渡します。
soup = BeautifulSoup(webpage.content, "lxml")
lxmlは高速なパーサーで、Beautiful SoupによってHTMLページを複雑なPythonオブジェクトに分解するために使用されます。一般的に得られるPythonオブジェクトには、4種類あります。
- Tag – It corresponds to HTML or XML tags, which include names and attributes.
- NavigableString – It corresponds to the text stored within a tag.
- BeautifulSoup – In fact, the entire parsed document.
- Comments – Finally, the leftover pieces of the HTML page that is not included in the above three categories.
物体抽出の正確なタグを発見する
このプロジェクトの中でも最も忙しい部分の一つは、関連情報を保存しているIDとタグを探し出すことです。前述のように、私たちはこのタスクを達成するためにウェブブラウザを使用しています。
ブラウザでウェブページを開き、右クリックを押して関連する要素を検査します。
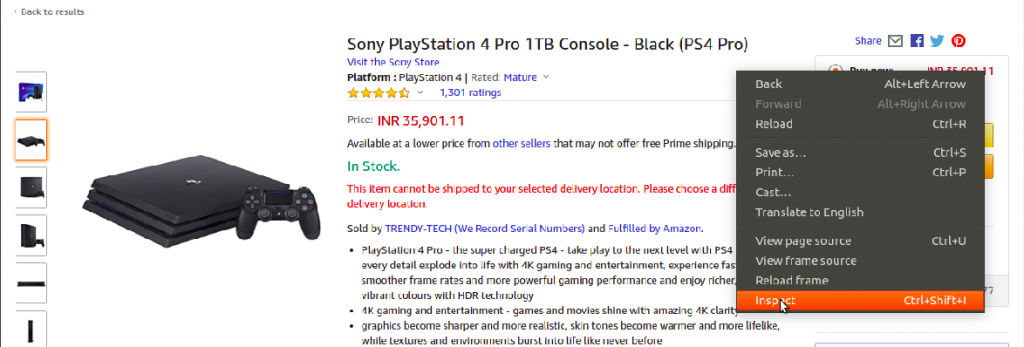
結果として、次の図に示されるように、画面の右側にパネルが開きます。
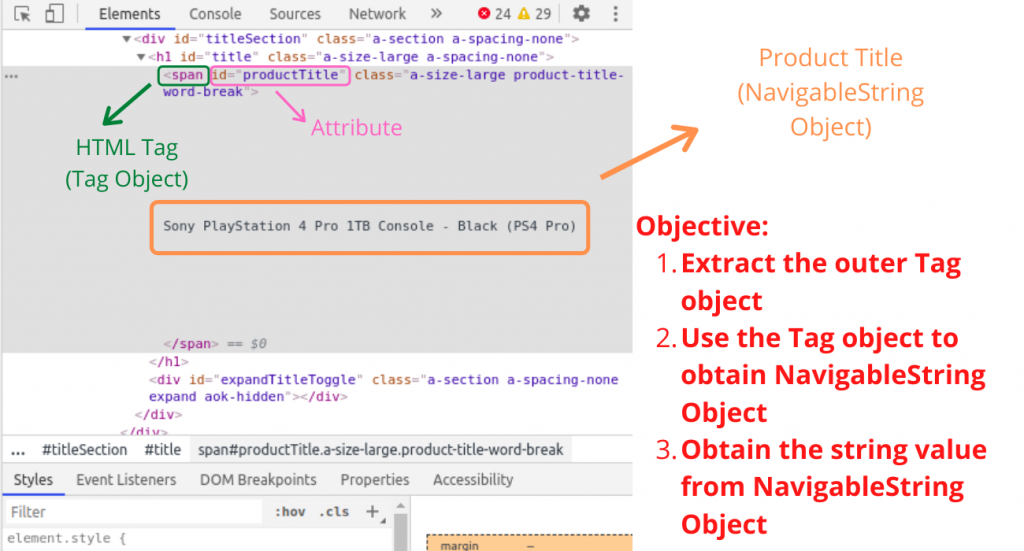
タグの値を取得したら、情報の抽出は簡単になります。ただし、Beautiful Soupオブジェクトに定義されている特定の関数を学ぶ必要があります。
商品タイトルの抽出
特定の属性を持つ特定のタグを検索するために使用可能なfind()関数を使用して、製品のタイトルを含むTagオブジェクトを見つけます。
# Outer Tag Object
title = soup.find("span", attrs={"id":'productTitle'})
それから、私たちはNavigableStringオブジェクトを取り出します。
# Inner NavigableString Object
title_value = title.string
最後に、余分な空白を取り除き、オブジェクトを文字列に変換します。
# Title as a string value
title_string = title_value.strip()
type()関数を使って、各変数の型を確認することができます。
# Printing types of values for efficient understanding
print(type(title))
print(type(title_value))
print(type(title_string))
print()
# Printing Product Title
print("Product Title = ", title_string)
出力:
<class 'bs4.element.Tag'>
<class 'bs4.element.NavigableString'>
<class 'str'>
Product Title = Sony PlayStation 4 Pro 1TB Console - Black (PS4 Pro)
同様に、「製品の価格」と「消費者評価」など、他の製品詳細のタグ値を把握する必要があります。
製品情報を抽出するためのPythonスクリプト
以下のPythonスクリプトは、製品の次の詳細を表示します:
- The Title of the Product
- The Price of the Product
- The Rating of the Product
- Number of Customer Reviews
- Product Availability
from bs4 import BeautifulSoup
import requests
# Function to extract Product Title
def get_title(soup):
try:
# Outer Tag Object
title = soup.find("span", attrs={"id":'productTitle'})
# Inner NavigableString Object
title_value = title.string
# Title as a string value
title_string = title_value.strip()
# # Printing types of values for efficient understanding
# print(type(title))
# print(type(title_value))
# print(type(title_string))
# print()
except AttributeError:
title_string = ""
return title_string
# Function to extract Product Price
def get_price(soup):
try:
price = soup.find("span", attrs={'id':'priceblock_ourprice'}).string.strip()
except AttributeError:
price = ""
return price
# Function to extract Product Rating
def get_rating(soup):
try:
rating = soup.find("i", attrs={'class':'a-icon a-icon-star a-star-4-5'}).string.strip()
except AttributeError:
try:
rating = soup.find("span", attrs={'class':'a-icon-alt'}).string.strip()
except:
rating = ""
return rating
# Function to extract Number of User Reviews
def get_review_count(soup):
try:
review_count = soup.find("span", attrs={'id':'acrCustomerReviewText'}).string.strip()
except AttributeError:
review_count = ""
return review_count
# Function to extract Availability Status
def get_availability(soup):
try:
available = soup.find("div", attrs={'id':'availability'})
available = available.find("span").string.strip()
except AttributeError:
available = ""
return available
if __name__ == '__main__':
# Headers for request
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
# The webpage URL
URL = "https://www.amazon.com/Sony-PlayStation-Pro-1TB-Console-4/dp/B07K14XKZH/"
# HTTP Request
webpage = requests.get(URL, headers=HEADERS)
# Soup Object containing all data
soup = BeautifulSoup(webpage.content, "lxml")
# Function calls to display all necessary product information
print("Product Title =", get_title(soup))
print("Product Price =", get_price(soup))
print("Product Rating =", get_rating(soup))
print("Number of Product Reviews =", get_review_count(soup))
print("Availability =", get_availability(soup))
print()
print()
出力:
Product Title = Sony PlayStation 4 Pro 1TB Console - Black (PS4 Pro)
Product Price = $473.99
Product Rating = 4.7 out of 5 stars
Number of Product Reviews = 1,311 ratings
Availability = In Stock.
「単一のAmazonのウェブページから情報を抽出する方法を知っているので、URLを変更するだけで同じスクリプトを複数のウェブページに適用することができます。」
さらに、今度はAmazonの検索結果のウェブページからリンクを取得しようとしてみましょう。
アマゾンの検索結果のウェブページからリンクを取得する
以前、ランダムなプレイステーション4に関する情報を入手しました。複数のプレイステーションの価格や評価を比較するために、そのような情報を抽出することは有益なアイデアです。
<\a>タグに囲まれたリンクをhref属性の値として見つけることができます。
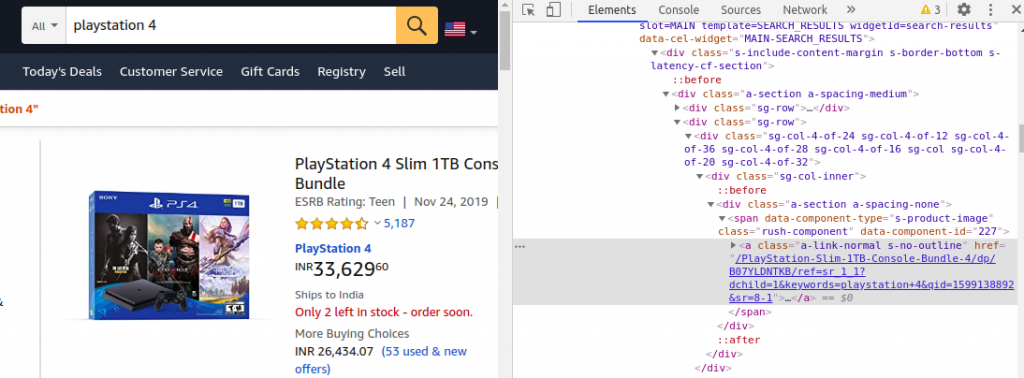
単一のリンクを取得する代わりに、find_all() 関数を使用してすべての類似リンクを抽出することができます。
# Fetch links as List of Tag Objects
links = soup.find_all("a", attrs={'class':'a-link-normal s-no-outline'})
find_all()関数は、複数のTagオブジェクトを含む反復可能なオブジェクトを返します。その結果、私たちは各Tagオブジェクトを選び、href属性の値として格納されているリンクを取り出します。
# Store the links
links_list = []
# Loop for extracting links from Tag Objects
for link in links:
links_list.append(link.get('href'))
私たちはリンクをリスト内に保存しています。これにより、各リンクを反復処理し、製品の詳細を抽出することができます。
# Loop for extracting product details from each link
for link in links_list:
new_webpage = requests.get("https://www.amazon.com" + link, headers=HEADERS)
new_soup = BeautifulSoup(new_webpage.content, "lxml")
print("Product Title =", get_title(new_soup))
print("Product Price =", get_price(new_soup))
print("Product Rating =", get_rating(new_soup))
print("Number of Product Reviews =", get_review_count(new_soup))
print("Availability =", get_availability(new_soup))
以前作成した機能を再利用して、商品情報を抽出するために使用します。複数のスープを生成するというこのプロセスはコードの動作を遅くしますが、その代わりに複数のモデルやディールの価格を正確に比較することができます。
複数のウェブページで製品の詳細を抽出するためのPythonスクリプト
以下は、複数のプレイステーションのお得情報をリストアップするための完全な動作するPythonスクリプトです。
from bs4 import BeautifulSoup
import requests
# Function to extract Product Title
def get_title(soup):
try:
# Outer Tag Object
title = soup.find("span", attrs={"id":'productTitle'})
# Inner NavigatableString Object
title_value = title.string
# Title as a string value
title_string = title_value.strip()
# # Printing types of values for efficient understanding
# print(type(title))
# print(type(title_value))
# print(type(title_string))
# print()
except AttributeError:
title_string = ""
return title_string
# Function to extract Product Price
def get_price(soup):
try:
price = soup.find("span", attrs={'id':'priceblock_ourprice'}).string.strip()
except AttributeError:
try:
# If there is some deal price
price = soup.find("span", attrs={'id':'priceblock_dealprice'}).string.strip()
except:
price = ""
return price
# Function to extract Product Rating
def get_rating(soup):
try:
rating = soup.find("i", attrs={'class':'a-icon a-icon-star a-star-4-5'}).string.strip()
except AttributeError:
try:
rating = soup.find("span", attrs={'class':'a-icon-alt'}).string.strip()
except:
rating = ""
return rating
# Function to extract Number of User Reviews
def get_review_count(soup):
try:
review_count = soup.find("span", attrs={'id':'acrCustomerReviewText'}).string.strip()
except AttributeError:
review_count = ""
return review_count
# Function to extract Availability Status
def get_availability(soup):
try:
available = soup.find("div", attrs={'id':'availability'})
available = available.find("span").string.strip()
except AttributeError:
available = "Not Available"
return available
if __name__ == '__main__':
# Headers for request
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US'})
# The webpage URL
URL = "https://www.amazon.com/s?k=playstation+4&ref=nb_sb_noss_2"
# HTTP Request
webpage = requests.get(URL, headers=HEADERS)
# Soup Object containing all data
soup = BeautifulSoup(webpage.content, "lxml")
# Fetch links as List of Tag Objects
links = soup.find_all("a", attrs={'class':'a-link-normal s-no-outline'})
# Store the links
links_list = []
# Loop for extracting links from Tag Objects
for link in links:
links_list.append(link.get('href'))
# Loop for extracting product details from each link
for link in links_list:
new_webpage = requests.get("https://www.amazon.com" + link, headers=HEADERS)
new_soup = BeautifulSoup(new_webpage.content, "lxml")
# Function calls to display all necessary product information
print("Product Title =", get_title(new_soup))
print("Product Price =", get_price(new_soup))
print("Product Rating =", get_rating(new_soup))
print("Number of Product Reviews =", get_review_count(new_soup))
print("Availability =", get_availability(new_soup))
print()
print()
出力:
Product Title = SONY PlayStation 4 Slim 1TB Console, Light & Slim PS4 System, 1TB Hard Drive, All the Greatest Games, TV, Music & More
Product Price = $357.00
Product Rating = 4.4 out of 5 stars
Number of Product Reviews = 32 ratings
Availability = In stock on September 8, 2020.
Product Title = Newest Sony Playstation 4 PS4 1TB HDD Gaming Console Bundle with Three Games: The Last of Us, God of War, Horizon Zero Dawn, Included Dualshock 4 Wireless Controller
Product Price = $469.00
Product Rating = 4.6 out of 5 stars
Number of Product Reviews = 211 ratings
Availability = Only 14 left in stock - order soon.
Product Title = PlayStation 4 Slim 1TB Console - Fortnite Bundle
Product Price =
Product Rating = 4.8 out of 5 stars
Number of Product Reviews = 2,715 ratings
Availability = Not Available
Product Title = PlayStation 4 Slim 1TB Console - Only On PlayStation Bundle
Product Price = $444.00
Product Rating = 4.7 out of 5 stars
Number of Product Reviews = 5,190 ratings
Availability = Only 1 left in stock - order soon.
上記のPythonスクリプトは、プレイステーションのリストに制限されません。URLをAmazonの検索結果への他のリンクに切り替えることもできます。例えば、ヘッドホンやイヤホンなどです。
前述の通り、HTMLページのレイアウトやタグは時間の経過とともに変わる可能性があり、上記のコードはこの点において無価値となるかもしれません。しかしながら、読者はウェブスクレイピングの概念とこの記事で学んだ技術を自宅に持ち帰る必要があります。
結論
「商品の価格の比較」から「消費者の傾向の分析」まで、ウェブスクレイピングには様々な利点があります。インターネットは誰もが利用できるし、Pythonは非常に簡単な言語なので、誰でも自分のニーズに合わせてウェブスクレイピングを行うことができます。
この記事が分かりやすかったら幸いです。質問やフィードバックがあれば、下記にコメントをお願いします。それでは、スクレイピングを楽しんでください!!

