JavaのHashMap – JavaにおけるHashMap
JavaのHashMapは、Javaで最も人気のあるCollectionクラスの一つです。JavaのHashMapはハッシュテーブルベースの実装です。JavaのHashMapは、Mapインターフェースを実装するAbstractMapクラスを拡張しています。
私の提案は、JavaのHashMapです。

-
- JavaのHashMapは、nullキーとnull値を許容します。
-
- HashMapは順序付けられたコレクションではありません。HashMapのエントリにはキーセットを通じて反復処理することができますが、エントリの順序はHashMapへの追加順序を保証するものではありません。
-
- HashMapは、Hashtableとほぼ同じですが、非同期でnullキーと値を許容します。
-
- HashMapは、マップのエントリを格納するために内部クラスのNode<K, V>を使用します。
-
- HashMapは、複数のシングルリンクリスト(バケットまたはビンと呼ばれる)にエントリを格納します。デフォルトのバケット数は16であり、常に2の累乗です。
-
- HashMapは、getおよびput操作において、キーのhashCode()およびequals()メソッドを使用します。したがって、HashMapキーオブジェクトはこれらのメソッドの良好な実装を提供する必要があります。これが、キーには不変クラス(例:文字列と整数)が適している理由です。
- JavaのHashMapはスレッドセーフではないため、マルチスレッド環境ではConcurrentHashMapクラスを使用するか、Collections.synchronizedMap()メソッドを使用して同期化されたマップを取得する必要があります。
JavaのHashMapのコンストラクタ
JavaのHashMapには4つのコンストラクタが提供されています。
-
- public HashMap(): 最も一般的に使用されるHashMapのコンストラクタです。このコンストラクタは、デフォルトの初期容量16とロードファクター0.75で空のHashMapを作成します。
-
- public HashMap(int initialCapacity): このHashMapのコンストラクタは、初期容量とロードファクター0.75を指定するために使用されます。HashMapに格納するマッピングの数を事前に知っている場合、再ハッシュを回避するのに役立ちます。
-
- public HashMap(int initialCapacity, float loadFactor): このHashMapのコンストラクタは、指定された初期容量とロードファクターを持つ空のHashMapを作成します。HashMapに格納する最大のマッピング数を事前に知っている場合に使用することができます。一般的なシナリオでは、スペースと時間のコストのトレードオフを提供するロードファクター0.75を避けるべきです。
- public HashMap(Map<? extends K, ? extends V> m): 指定されたマップとロードファクター0.75を持つ同じマッピングを持つマップを作成します。
JavaのHashMapのコンストラクタの例を示します。
以下のコードスニペットは、上記のすべてのコンストラクタを使用したHashMapの例を示しています。
Map<String, String> map1 = new HashMap<>();
Map<String, String> map2 = new HashMap<>(2^5);
Map<String, String> map3 = new HashMap<>(32,0.80f);
Map<String,String> map4 = new HashMap<>(map1);
JavaのHashMapメソッド
JavaのHashMapの重要なメソッドを見てみましょう。
-
- public void clear(): このHashMapのメソッドは、すべてのマッピングを削除し、HashMapを空にします。
-
- public boolean containsKey(Object key): このメソッドは、指定されたキーが存在する場合は「true」を返し、存在しない場合は「false」を返します。
-
- public boolean containsValue(Object value): このHashMapのメソッドは、指定された値が存在する場合は「true」を返し、存在しない場合は「false」を返します。
-
- public Set<Map.Entry<K,V>> entrySet(): このメソッドは、HashMapのマッピングのSetビューを返します。このセットは、マップによってバックアップされるため、マップの変更はセットに反映され、逆もまた然りです。
-
- public V get(Object key): 指定されたキーにマッピングされた値を返します。キーにマッピングがない場合はnullを返します。
-
- public boolean isEmpty(): キーと値のマッピングが存在しない場合はtrueを返すユーティリティメソッドです。
-
- public Set keySet(): このマップに含まれるキーのSetビューを返します。このセットはマップによってバックアップされるため、マップの変更はセットに反映され、逆もまた然りです。
-
- public V put(K key, V value): 指定されたキーに指定された値をこのマップに関連付けます。マップが既にキーのマッピングを持っている場合は、古い値が置き換えられます。
-
- public void putAll(Map<? extends K, ? extends V> m): 指定されたマップからすべてのマッピングをこのマップにコピーします。これらのマッピングは、指定されたマップ内の現在のキーのいずれかに対して、このマップが持っていた任意のマッピングを置き換えます。
-
- public V remove(Object key): 指定されたキーに対応するマッピングをこのマップから削除します(存在する場合)。
-
- public int size(): このマップのキーと値のマッピングの数を返します。
- public Collection values(): このマップに含まれる値のCollectionビューを返します。このコレクションはマップによってバックアップされるため、マップの変更はコレクションに反映され、逆もまた然りです。
Java 8で導入されたHashMapの新しいメソッドはたくさんあります。
-
- public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction): 指定されたキーが値と関連付けられていない場合(またはnullにマップされている場合)、このメソッドは与えられたマッピング関数を使用してその値を計算し、それをHashMapに入力します。
public V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction): 指定されたキーに対する値が存在し、非nullである場合、現在のキーとその現在のマッピングされた値を使用して新しいマッピングを計算しようとします。
public V compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction): このHashMapメソッドは、指定されたキーとその現在のマッピングされた値のマッピングを計算しようとします。
public void forEach(BiConsumer<? super K, ? super V> action): このメソッドは、このマップの各エントリに指定されたアクションを実行します。
public V getOrDefault(Object key, V defaultValue): getと同じですが、指定されたキーに対してマッピングが見つからない場合はdefaultValueが返されます。
public V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction): 指定されたキーが値と関連付けられていない場合、またはnullに関連付けられている場合、それを指定された非null値で関連付けます。そうでない場合、関連付けられた値を、指定されたリマッピング関数の結果で置き換えます。結果がnullの場合は削除します。
public V putIfAbsent(K key, V value): 指定されたキーが値と関連付けられていない場合(またはnullにマップされている場合)、それを指定された値で関連付けます。nullが返され、それ以外の場合は現在の値が返されます。
public boolean remove(Object key, Object value): 指定されたキーに対応するエントリを指定された値にマッピングされている場合にのみ削除します。
public boolean replace(K key, V oldValue, V newValue): 指定されたキーに対応するエントリを、現在の値が指定された値にマッピングされている場合にのみ置換します。
public V replace(K key, V value): 指定されたキーに対応するエントリを、現在の値がマッピングされている場合にのみ置換します。
public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function): 各エントリの値を、そのエントリ上で指定された関数を呼び出した結果で置き換えます。
JavaのHashMapの例
こちらは、HashMapの一般的な使用方法に関するシンプルなJavaプログラムです。
package com.scdev.examples;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class HashMapExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1"); // put example
map.put("2", "2");
map.put("3", "3");
map.put("4", null); // null value
map.put(null, "100"); // null key
String value = map.get("3"); // get example
System.out.println("Key = 3, Value = " + value);
value = map.getOrDefault("5", "Default Value");
System.out.println("Key = 5, Value=" + value);
boolean keyExists = map.containsKey(null);
boolean valueExists = map.containsValue("100");
System.out.println("keyExists=" + keyExists + ", valueExists=" + valueExists);
Set<Entry<String, String>> entrySet = map.entrySet();
System.out.println(entrySet);
System.out.println("map size=" + map.size());
Map<String, String> map1 = new HashMap<>();
map1.putAll(map);
System.out.println("map1 mappings= " + map1);
String nullKeyValue = map1.remove(null);
System.out.println("map1 null key value = " + nullKeyValue);
System.out.println("map1 after removing null key = " + map1);
Set<String> keySet = map.keySet();
System.out.println("map keys = " + keySet);
Collection<String> values = map.values();
System.out.println("map values = " + values);
map.clear();
System.out.println("map is empty=" + map.isEmpty());
}
}
以下は、上記のJava HashMapの例題プログラムの出力です。
Key = 3, Value = 3
Key = 5, Value=Default Value
keyExists=true, valueExists=true
[null=100, 1=1, 2=2, 3=3, 4=null]
map size=5
map1 mappings= {null=100, 1=1, 2=2, 3=3, 4=null}
map1 null key value = 100
map1 after removing null key = {1=1, 2=2, 3=3, 4=null}
map keys = [null, 1, 2, 3, 4]
map values = [100, 1, 2, 3, null]
map is empty=true
JavaでHashMapはどのように動作しますか?
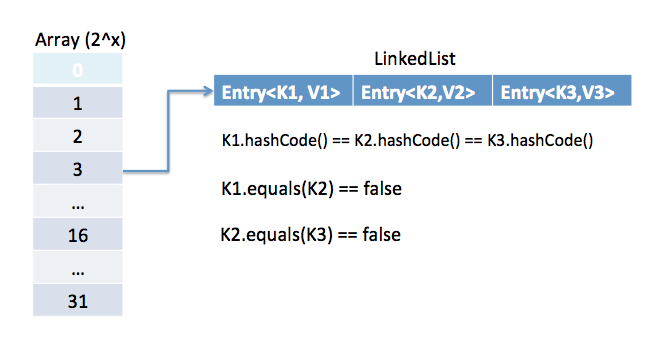
JavaのHashMapのロードファクターを説明してください。
ロードファクターは、HashMapがリハッシュされ、バケットのサイズが増加するタイミングを計算するために使用されます。バケットまたはキャパシティのデフォルト値は16で、ロードファクターは0.75です。リハッシュのしきい値は、キャパシティとロードファクターを乗算して計算されます。したがって、デフォルトのしきい値は12になります。つまり、HashMapに12以上のマッピングがあると、リハッシュが行われ、ビンの数が2のべき乗である32に増加します。HashMapのキャパシティは常に2のべき乗であることに注意してください。デフォルトのロードファクター0.75は、スペースと時間の複雑さのトレードオフを提供します。ただし、必要に応じて異なる値に設定することもできます。スペースを節約したい場合は、値を0.80または0.90に増やすことができますが、その場合、get / put操作にはより多くの時間がかかります。
Java の HashMap の keySet
JavaのHashMapのkeySetメソッドは、HashMap内のキーのSetビューを返します。このSetビューはHashMapによって支えられており、HashMapの変更はSetに反映され、逆もまた然りです。以下には、HashMapのkeySetの例を示す簡単なプログラムと、マップによって支えられていないkeySetを取得する方法があります。
package com.scdev.examples;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
public class HashMapKeySetExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put("3", "3");
Set<String> keySet = map.keySet();
System.out.println(keySet);
map.put("4", "4");
System.out.println(keySet); // keySet is backed by Map
keySet.remove("1");
System.out.println(map); // map is also modified
keySet = new HashSet<>(map.keySet()); // copies the key to new Set
map.put("5", "5");
System.out.println(keySet); // keySet is not modified
}
}
上記のプログラムの出力結果から、keySetがmapによってサポートされていることが明確になります。
[1, 2, 3]
[1, 2, 3, 4]
{2=2, 3=3, 4=4}
[2, 3, 4]
Java の HashMap の値
JavaのHashMapのvaluesメソッドは、Map内の値のコレクションビューを返します。このコレクションはHashMapでバックアップされているため、HashMapの変更は値のコレクションに反映され、逆もまた然りです。以下の簡単な例は、HashMapの値のコレクションのこの挙動を確認します。
package com.scdev.examples;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
public class HashMapValuesExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put("3", null);
map.put("4", null);
map.put(null, "100");
Collection<String> values = map.values();
System.out.println("map values = " + values);
map.remove(null);
System.out.println("map values after removing null key = " + values);
map.put("5", "5");
System.out.println("map values after put = " + values);
System.out.println(map);
values.remove("1"); // changing values collection
System.out.println(map); // updates in map too
}
}
上記のプログラムの出力は以下の通りです。
map values = [100, 1, 2, null, null]
map values after removing null key = [1, 2, null, null]
map values after put = [1, 2, null, null, 5]
{1=1, 2=2, 3=null, 4=null, 5=5}
{2=2, 3=null, 4=null, 5=5}
JavaのHashMapのentrySet
JavaのHashMapのentrySetメソッドは、マッピングのSetビューを返します。このentrySetはHashMapによってバックアップされているため、マップの変更はエントリーセットに反映され、逆も同様です。以下のHashMapのentrySetの例プログラムをご覧ください。
package com.scdev.examples;
import java.util.AbstractMap;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class HashMapEntrySetExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", null);
map.put(null, "100");
Set<Entry<String,String>> entrySet = map.entrySet();
Iterator<Entry<String, String>> iterator = entrySet.iterator();
Entry<String, String> next = null;
System.out.println("map before processing = "+map);
System.out.println("entrySet before processing = "+entrySet);
while(iterator.hasNext()){
next = iterator.next();
System.out.println("Processing on: "+next.getValue());
if(next.getKey() == null) iterator.remove();
}
System.out.println("map after processing = "+map);
System.out.println("entrySet after processing = "+entrySet);
Entry<String, String> simpleEntry = new AbstractMap.SimpleEntry<String, String>("1","1");
entrySet.remove(simpleEntry);
System.out.println("map after removing Entry = "+map);
System.out.println("entrySet after removing Entry = "+entrySet);
}
}
上記のプログラムによって生成された出力は以下の通りです。
map before processing = {null=100, 1=1, 2=null}
entrySet before processing = [null=100, 1=1, 2=null]
Processing on: 100
Processing on: 1
Processing on: null
map after processing = {1=1, 2=null}
entrySet after processing = [1=1, 2=null]
map after removing Entry = {2=null}
entrySet after removing Entry = [2=null]
JavaのHashMapのputIfAbsent
Java 8で導入されたHashMapのputIfAbsentメソッドのシンプルな例。
package com.scdev.examples;
import java.util.HashMap;
import java.util.Map;
public class HashMapPutIfAbsentExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", null);
map.put(null, "100");
System.out.println("map before putIfAbsent = "+map);
String value = map.putIfAbsent("1", "4");
System.out.println("map after putIfAbsent = "+map);
System.out.println("putIfAbsent returns: "+value);
System.out.println("map before putIfAbsent = "+map);
value = map.putIfAbsent("3", "3");
System.out.println("map after putIfAbsent = "+map);
System.out.println("putIfAbsent returns: "+value);
}
}
上記のプログラムの出力は、-
map before putIfAbsent = {null=100, 1=1, 2=null}
map after putIfAbsent = {null=100, 1=1, 2=null}
putIfAbsent returns: 1
map before putIfAbsent = {null=100, 1=1, 2=null}
map after putIfAbsent = {null=100, 1=1, 2=null, 3=3}
putIfAbsent returns: null
JavaのHashMapのforEachメソッドを言葉を変えずに日本語で表現すると、 “`Java HashMapのforEach“` です。
Java 8で導入されたHashMapのforEachメソッドは非常に便利なメソッドです。このメソッドを使用すると、与えられたアクションを、すべてのエントリが処理されるか、アクションが例外をスローするまで、マップ内の各エントリに対して実行することができます。
package com.scdev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiConsumer;
public class HashMapForEachExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", null);
map.put(null, "100");
BiConsumer<String, String> action = new MyBiConsumer();
map.forEach(action);
//lambda expression example
System.out.println("\nHashMap forEach lambda example\n");
map.forEach((k,v) -> {System.out.println("Key = "+k+", Value = "+v);});
}
}
class MyBiConsumer implements BiConsumer<String, String> {
@Override
public void accept(String t, String u) {
System.out.println("Key = " + t);
System.out.println("Processing on value = " + u);
}
}
上記のHashMapのforEachの例プログラムの出力は次のとおりです。
Key = null
Processing on value = 100
Key = 1
Processing on value = 1
Key = 2
Processing on value = null
HashMap forEach lambda example
Key = null, Value = 100
Key = 1, Value = 1
Key = 2, Value = null
JavaのHashMapのreplaceAllメソッドを日本語で同義の表現で述べると、「JavaのHashMapのreplaceAllメソッドは」です。
HashMapのreplaceAllメソッドは、与えられた関数をエントリごとに呼び出した結果でエントリの値を置き換えるために使用することができます。このメソッドはJava 8で追加され、このメソッドの引数にはラムダ式を使用することができます。
package com.scdev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiFunction;
public class HashMapReplaceAllExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put(null, "100");
System.out.println("map before replaceAll = " + map);
BiFunction<String, String, String> function = new MyBiFunction();
map.replaceAll(function);
System.out.println("map after replaceAll = " + map);
// replaceAll using lambda expressions
map.replaceAll((k, v) -> {
if (k != null) return k + v;
else return v;});
System.out.println("map after replaceAll lambda expression = " + map);
}
}
class MyBiFunction implements BiFunction<String, String, String> {
@Override
public String apply(String t, String u) {
if (t != null)
return t + u;
else
return u;
}
}
上記のHashMapのreplaceAllプログラムの出力は次のとおりです。
map before replaceAll = {null=100, 1=1, 2=2}
map after replaceAll = {null=100, 1=11, 2=22}
map after replaceAll lambda example = {null=100, 1=111, 2=222}
JavaのHashMapのcomputeIfAbsent
HashMapのcomputeIfAbsentメソッドは、キーがマップに存在しない場合にのみ値を計算します。値を計算した後、それがnullでない場合にマップに入れられます。
package com.scdev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.function.Function;
public class HashMapComputeIfAbsent {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "10");
map.put("2", "20");
map.put(null, "100");
Function<String, String> function = new MyFunction();
map.computeIfAbsent("3", function); //key not present
map.computeIfAbsent("2", function); //key already present
//lambda way
map.computeIfAbsent("4", v -> {return v;});
map.computeIfAbsent("5", v -> {return null;}); //null value won't get inserted
System.out.println(map);
}
}
class MyFunction implements Function<String, String> {
@Override
public String apply(String t) {
return t;
}
}
上記のプログラムの出力は次のようになります。
{null=100, 1=10, 2=20, 3=3, 4=4}
JavaのHashMapのcomputeIfPresent
Java HashMapのcomputeIfPresentメソッドは、指定されたキーが存在し、値がnullではない場合に、値を再計算します。もし関数がnullを返す場合、マッピングは削除されます。
package com.scdev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiFunction;
public class HashMapComputeIfPresentExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "10");
map.put("2", "20");
map.put(null, "100");
map.put("10", null);
System.out.println("map before computeIfPresent = " + map);
BiFunction<String, String, String> function = new MyBiFunction1();
for (String key : map.keySet()) {
map.computeIfPresent(key, function);
}
System.out.println("map after computeIfPresent = " + map);
map.computeIfPresent("1", (k,v) -> {return null;}); // mapping will be removed
System.out.println("map after computeIfPresent = " + map);
}
}
class MyBiFunction1 implements BiFunction<String, String, String> {
@Override
public String apply(String t, String u) {
return t + u;
}
}
HashMapのcomputeIfPresentの例によって生成される出力は、次の通りです。
map before computeIfPresent = {null=100, 1=10, 2=20, 10=null}
map after computeIfPresent = {null=null100, 1=110, 2=220, 10=null}
map after computeIfPresent = {null=null100, 2=220, 10=null}
JavaのHashMapのcomputeメソッドを日本語で言い換えると、一つのオプションは「JavaのHashMapのcomputeメソッドを実行する」となります。
もし、キーと値に基づいて全てのマッピングに関数を適用したい場合は、computeメソッドを使用する必要があります。もしマッピングが存在せずにこのメソッドが使用された場合、compute関数の値はnullになります。
package com.scdev.examples;
import java.util.HashMap;
import java.util.Map;
public class HashMapComputeExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put(null, "10");
map.put("10", null);
System.out.println("map before compute = "+map);
for (String key : map.keySet()) {
map.compute(key, (k,v) -> {return k+v;});
}
map.compute("5", (k,v) -> {return k+v;}); //key not present, v = null
System.out.println("map after compute = "+map);
}
}
HashMapのcomputeの例の出力は次のようになります。
map before compute = {null=10, 1=1, 2=2, 10=null}
map after compute = {null=null10, 1=11, 2=22, 5=5null, 10=10null}
JavaのHashMapのマージ
指定されたキーが存在しないか、nullと関連付けられている場合、与えられた非nullの値で関連付けます。それ以外の場合は、与えられたリマッピング関数の結果で関連付けられた値を置き換えます。結果がnullの場合は、削除します。
package com.scdev.examples;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
public class HashMapMergeExample {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
map.put("2", "2");
map.put(null, "10");
map.put("10", null);
for (Entry<String, String> entry : map.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
//merge throws NullPointerException if key or value is null
if(key != null && value != null)
map.merge(entry.getKey(), entry.getValue(),
(k, v) -> {return k + v;});
}
System.out.println(map);
map.merge("5", "5", (k, v) -> {return k + v;}); // key not present
System.out.println(map);
map.merge("1", "1", (k, v) -> {return null;}); // method return null, so remove
System.out.println(map);
}
}
上記のプログラムの出力は次の通りです。
{null=10, 1=11, 2=22, 10=null}
{null=10, 1=11, 2=22, 5=5, 10=null}
{null=10, 2=22, 5=5, 10=null}
これでJavaのHashMapについては以上です。大事な点を見落としていないことを願っています。もし気に入ったなら、他の人とも共有してください。参考:APIドキュメント。

