Pythonのデータを標準化するためにStandardScaler()関数を使用する。
皆さん、こんにちは!この記事では、Pythonでの最も重要な前処理技術の1つ、StandardScaler()関数を使用した標準化に焦点を当てます。
では、始めましょう!!
標準化の必要性
標準化に入る前に、スケーリングの概念をまず理解しましょう。
特徴のスケーリングは、データセットを使用してアルゴリズムのモデリングを行う際に重要なステップです。通常、モデリングの目的で使用されるデータはさまざまな手段で導出されます。
- Questionnaire
- Surveys
- Research
- Scraping, etc.
したがって、取得されたデータにはさまざまな次元やスケールの特徴が含まれています。データの特徴の異なるスケールは、データセットのモデリングに悪影響を及ぼします。
誤分類エラーや正確性の率に偏りをもたらすため、モデリング前にデータをスケールすることが必要です。
これは標準化が関係してくる時です。
標準化は、データの統計分布を以下の形式に変換することで、データをスケールフリーにするスケーリング技術です。
- mean – 0 (zero)
- standard deviation – 1
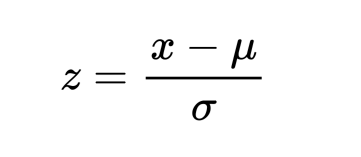
これにより、データセット全体がゼロ平均かつ単位分散でスケーリングされます。
さあ、次のセクションで標準化の概念を実装してみましょう。
PythonのsklearnのStandardScaler()関数を日本語に言い換えると、以下のようになります:
PythonのsklearnのStandardScaler()関数
Pythonのsklearnライブラリは、StandardScaler()関数を提供しています。この関数を使用すると、データの値を標準の形式に標準化することができます。
構文:
object = StandardScaler()
object.fit_transform(data)
上記の構文によれば、まずStandardScaler()関数のオブジェクトを作成します。さらに、fit_transform()を割り当てられたオブジェクトと一緒に使用してデータを変換し、標準化します。
注意:標準化は正規分布に従うデータ値にのみ適用されます。
StandardScaler()関数を使用してデータを標準化する。
以下の例を見てみてください!
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
dataset = load_iris()
object= StandardScaler()
# Splitting the independent and dependent variables
i_data = dataset.data
response = dataset.target
# standardization
scale = object.fit_transform(i_data)
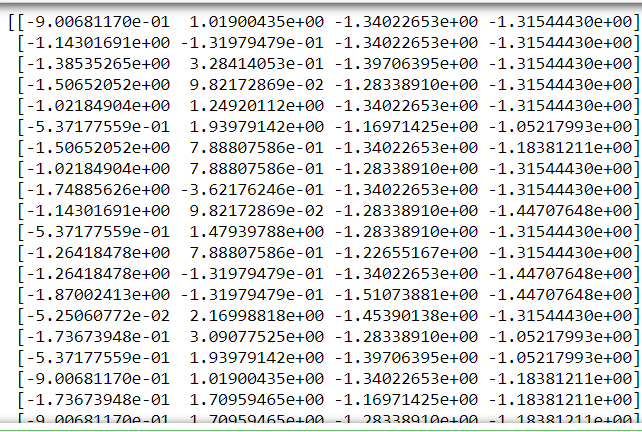
print(scale)
説明:
-
- 必要なライブラリをインポートします。StandardScaler関数を使うためにsklearnライブラリをインポートしました。
-
- データセットをロードします。ここでは、sklearn.datasetsライブラリからIRISデータセットを使用しました。データセットはこちらで入手できます。
-
- StandardScaler()関数にオブジェクトを設定します。
-
- 独立変数と目的変数を上記のように分離します。
- fit_transform()関数を使ってデータセットに関数を適用します。
出力:
結論
これにより、このトピックは終了しました。もし質問がある場合は、下にコメントしてください。
Pythonに関連するさらなる投稿については、Python with JournalDevでお楽しみに。その間、学ぶことを楽しんでください! 🙂

