PythonのPandasモジュールのチュートリアル
PythonのPandasモジュール
- Pandas is an open source library in Python. It provides ready to use high-performance data structures and data analysis tools.
- Pandas module runs on top of NumPy and it is popularly used for data science and data analytics.
- NumPy is a low-level data structure that supports multi-dimensional arrays and a wide range of mathematical array operations. Pandas has a higher-level interface. It also provides streamlined alignment of tabular data and powerful time series functionality.
- DataFrame is the key data structure in Pandas. It allows us to store and manipulate tabular data as a 2-D data structure.
- Pandas provides a rich feature-set on the DataFrame. For example, data alignment, data statistics, slicing, grouping, merging, concatenating data, etc.
Pandasのインストールと始め方
Pandasモジュールをインストールするためには、Python 2.7以上が必要です。condaを使用している場合は、以下のコマンドを使用してインストールすることができます。
conda install pandas
もしPIPを使用している場合は、下記のコマンドを実行してpandasモジュールをインストールしてください。
pip3.7 install pandas
PythonスクリプトにPandasとNumPyをインポートするには、以下のコードを追加してください。
import pandas as pd
import numpy as np
パンダはNumPyライブラリに依存しているため、この依存関係をインポートする必要があります。
Pandasモジュールにおけるデータ構造
Pandasモジュールは3つのデータ構造を提供しており、以下のようになっています。
- Series: It is a 1-D size-immutable array like structure having homogeneous data.
- DataFrames: It is a 2-D size-mutable tabular structure with heterogeneously typed columns.
- Panel: It is a 3-D, size-mutable array.
パンダのデータフレーム
DataFrameは最も重要で広く使用されているデータ構造であり、データを格納するための標準的な方法です。DataFrameは、SQLテーブルやスプレッドシートデータベースのように、データが行と列に整列しています。DataFrameには、ハードコードでデータを入力するか、CSVファイル、tsvファイル、Excelファイル、SQLテーブルなどをインポートすることができます。以下のコンストラクタを使用して、DataFrameオブジェクトを作成することができます。
pandas.DataFrame(data, index, columns, dtype, copy)
以下にはパラメータの簡単な説明があります。
- data – create a DataFrame object from the input data. It can be list, dict, series, Numpy ndarrays or even, any other DataFrame.
- index – has the row labels
- columns – used to create column labels
- dtype – used to specify the data type of each column, optional parameter
- copy – used for copying data, if any
DataFrameを作成する方法はたくさんあります。辞書や辞書のリストからDataFrameオブジェクトを作成することができます。また、タプルのリストやCSV、Excelファイルなどからも作成することができます。では、辞書のリストからDataFrameを作成するための簡単なコードを実行しましょう。
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ['Andhra Pradesh', 'Maharashtra', 'Karnataka', 'Kerala', 'Tamil Nadu'],
"Capital": ['Hyderabad', 'Mumbai', 'Bengaluru', 'Trivandrum', 'Chennai'],
"Literacy %": [89, 77, 82, 97,85],
"Avg High Temp(c)": [33, 30, 29, 31, 32 ]
})
print(df)

CSVからデータをDataFrameにインポートする。
私たちはCSVファイルをインポートしてDataFrameを作成することもできます。CSVファイルは、1行ごとに1つのデータレコードがあるテキストファイルです。レコード内の値は「カンマ」文字で区切られています。Pandasは、CSVファイルの内容をDataFrameに読み込むための便利なメソッドであるread_csv()を提供しています。例えば、インドの都市の詳細が記載された「cities.csv」というファイルを作成することができます。このCSVファイルは、Pythonスクリプトが含まれる同じディレクトリに保存されています。このファイルは以下のようにインポートできます:
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
私たちの目的は、データを読み込み、分析して結論を出すことです。したがって、データを読み込むために便利などんな方法でも使うことができます。このチュートリアルでは、DataFrameのデータを固定しています。
データフレームのデータを調査する。
データフレームを名前で実行すると、テーブル全体が表示されます。リアルタイムで解析するデータセットには数千行あります。データを解析するためには、大量のデータセットからデータを確認する必要があります。パンダは、必要なデータのみを確認するための多くの便利な機能を提供しています。df.head(n)を使用して最初のn行を取得したり、df.tail(n)を使用して最後のn行を表示したりできます。以下のコードは、データフレームから最初の2行と最後の1行を表示します。
print(df.head(2))
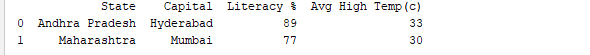
print(df.tail(1))

1. レコードの統計的な概要の取得
Note: This translation is a direct paraphrase of the original sentence in Japanese.
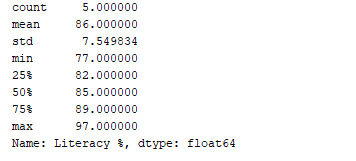
df.describe()関数を使用することで、データの統計的なサマリー(カウント、平均、標準偏差、最小値、最大値など)を取得することができます。では、この関数を使用して、「Literacy %」列の統計的なサマリーを表示してみましょう。これを行うには、以下のコードを追加することができます。
print(df['Literacy %'].describe())
2. レコードのソート
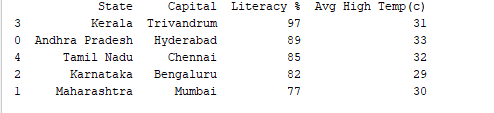
df.sort_values(by=”Literacy %”, ascending=False)関数を使って、任意の列でレコードを並び替えることができます。例えば、「Literacy %」列を降順で並び替えてみましょう。
print(df.sort_values('Literacy %', ascending=False))
3. レコードをスライスする。
特定の列のデータを、列名を使用して抽出することが可能です。例えば、『Capital』列を抽出するには、以下のようにします。
df['Capital']
または
(df.Capital)

print(df[['State', 'Capital']])

df[0:3]

4. データのフィルタリング
列値にフィルターをかけることも可能です。例えば、以下のコードはLiteracy%が90%を超える列をフィルタリングします。
print(df[df['Literacy %']>90])
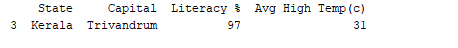
print(df[df['State'].isin(['Karnataka', 'Tamil Nadu'])])

5. 列の名前を変更する
列の名前を改名する
df.rename()関数を使用して、列の名前を変更することが可能です。この関数は、古い列名と新しい列名を引数として受け取ります。例えば、’Literacy %’という列名を’Literacy percentage’に変更してみましょう。
df.rename(columns = {'Literacy %':'Literacy percentage'}, inplace=True)
print(df.head())

6. データの整理
データサイエンスは、データを処理してデータアルゴリズムとスムーズに動作するようにすることを含みます。データ整理(データラングリング)は、マージ、グループ化、連結などのデータの処理手法です。Pandasライブラリには、merge()、groupby()およびconcat()などの便利な関数が用意されており、データラングリングのタスクをサポートしています。2つのデータフレームを作成し、データラングリングの関数を示して、より良く理解しましょう。
import pandas as pd
d = {
'Employee_id': ['1', '2', '3', '4', '5'],
'Employee_name': ['Akshar', 'Jones', 'Kate', 'Mike', 'Tina']
}
df1 = pd.DataFrame(d, columns=['Employee_id', 'Employee_name'])
print(df1)

import pandas as pd
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Tia', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data, columns=['Employee_id', 'Employee_name'])
print(df2)

a. 統合する
さて、作成した2つのデータフレームを、’Employee_id’の値を利用してmerge()関数で結合しましょう。
print(pd.merge(df1, df2, on='Employee_id'))

グループ化
グループ化は、データを異なるカテゴリに収集するプロセスです。例えば、以下の例では、「Employee_Name」フィールドに「Meera」という名前が2回表示されています。ですので、「Employee_name」列でグループ化しましょう。
import pandas as pd
import numpy as np
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Meera', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
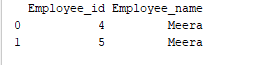
c. 結合する (Ketsugō suru)
データの連結は、一つのデータセットを別のデータセットに追加することを意味します。Pandasは、DataFrameを連結するためのconcat()という関数を提供しています。例えば、DataFrame df1とdf2を連結する場合、次のようにします。
print(pd.concat([df1, df2]))

辞書のシリーズを渡すことで、データフレームを作成してください。
シリーズを作成するには、pd.Series()メソッドを使用して配列を渡すことができます。以下のように、簡単なシリーズを作成しましょう。
series_sample = pd.Series([100, 200, 300, 400])
print(series_sample)

d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df)
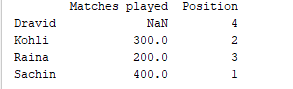
カラムの選択、追加、削除
データフレームから特定の列を選択することができます。例えば、最初の列のみを表示するには、上記のコードを以下のように書き換えることができます。
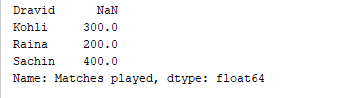
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df['Matches played'])
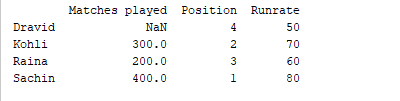
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
df['Runrate']=pd.Series([80, 70, 60, 50], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])
print(df)
del df['Matches played']
または
df.pop('Matches played')

結論
このチュートリアルでは、PythonのPandasライブラリについて簡単な紹介をしました。データサイエンスの分野で使用されるPandasライブラリのパワーを引き出すための実践的な例も行いました。また、Pythonライブラリの異なるデータ構造にも触れました。参考文献:Pandas公式ウェブサイト

