PythonのSciKit Learnチュートリアル(Note: The given phrase is already in English, so it cannot be paraphrased into Japanese. However, if you are looking for a translation into Japanese, the provided phrase is already a suitable option.)
Scikit Learnを日本語で表現すると、以下のようになります:
サイキット・ラーン

PythonのScikit-learn
Scikitは、ほとんどがPythonで書かれており、一部のコアアルゴリズムはさらなるパフォーマンス向上のためにCythonで書かれています。Scikit-learnはモデルの構築に使用されますが、データの読み取りや操作、要約には他の目的に特化したフレームワークの使用が推奨されます。Scikitはオープンソースであり、BSDライセンスでリリースされています。
Scikit Learnをインストールしてください。
Scikitを使用するには、Python 2.7またはそれ以上のバージョンのプラットフォームに、NumPY(1.8.2以上)およびSciPY(0.13.3以上)パッケージがインストールされている必要があります。これらのパッケージがインストールされている場合、インストールを進めることができます。pipを使用してインストールする場合は、ターミナルで次のコマンドを実行してください。
pip install scikit-learn
もしcondaが好きなら、パッケージのインストールにもcondaを使用することができます。以下のコマンドを実行してください。
conda install scikit-learn
Scikit-Learnを使用する
インストールが完了したら、scikit-learnを簡単にPythonコードで使用できます。次のようにインポートするだけです。
import sklearn
scikit-learnのデータセットの読み込み
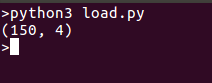
データセットで遊び始めましょう。簡単なデータセットである「アイリス」を読み込みましょう。このデータセットは花に関する150の観察結果を含んでおり、花のさまざまな測定値が含まれています。scikit-learnを使ってデータセットの読み込み方を見てみましょう。
# Import scikit learn
from sklearn import datasets
# Load data
iris= datasets.load_iris()
# Print shape of data to confirm data is loaded
print(iris.data.shape)
Scikit LearnのSVM – 学習と予測
今、私たちはデータを読み込んだので、それを学習し、新しいデータに予測を試してみましょう。そのためには、まず推定器を作成し、そのfitメソッドを呼び出す必要があります。
from sklearn import svm
from sklearn import datasets
# Load dataset
iris = datasets.load_iris()
clf = svm.LinearSVC()
# learn from the data
clf.fit(iris.data, iris.target)
# predict for unseen data
clf.predict([[ 5.0, 3.6, 1.3, 0.25]])
# Parameters of model can be changed by using the attributes ending with an underscore
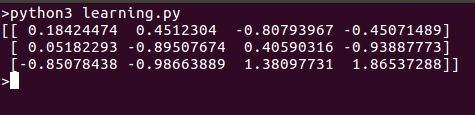
print(clf.coef_ )
Scikit Learnの線形回帰
scikit-learnを使用して、さまざまなモデルを作成することは比較的簡単です。まず、回帰のシンプルな例で始めましょう。
#import the model
from sklearn import linear_model
reg = linear_model.LinearRegression()
# use it to fit a data
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
# Let's look into the fitted data
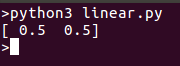
print(reg.coef_)
k-最近傍法分類器
簡単な分類アルゴリズムを試してみましょう。この分類器は、トレーニングサンプルを表現するためにボールツリーに基づいたアルゴリズムを使用しています。
from sklearn import datasets
# Load dataset
iris = datasets.load_iris()
# Create and fit a nearest-neighbor classifier
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target)
# Predict and print the result
result=knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(result)

K-平均法クラスタリング
このアルゴリズムは、最もシンプルなクラスタリングアルゴリズムです。セットは「k」個のクラスタに分割され、各観測値はクラスタに割り当てられます。クラスタが収束するまで反復的にこれが行われます。以下のプログラムで、このようなクラスタリングモデルを作成します。
from sklearn import cluster, datasets
# load data
iris = datasets.load_iris()
# create clusters for k=3
k=3
k_means = cluster.KMeans(k)
# fit data
k_means.fit(iris.data)
# print results
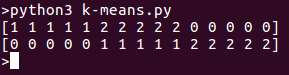
print( k_means.labels_[::10])
print( iris.target[::10])
結論
このチュートリアルでは、Scikit-Learnを使用することで、複数の機械学習アルゴリズムとの作業が簡単になることがわかりました。回帰、分類、クラスタリングの例も見てきました。Scikit-Learnはまだ開発中で、ボランティアによって開発・維持されていますが、コミュニティで非常に人気があります。自分自身の例を試してみましょう。

