Pythonでの損失関数 – 簡単な実装
損失関数はPythonにおいて機械学習モデルの重要な一部です。これらの関数は、モデルの予測された出力が実際の出力とどれだけ異なるかを教えてくれます。
この差を計算する方法は複数あります。このチュートリアルでは、より人気のある損失関数について見ていきます。
このチュートリアルでは、以下の4つの損失関数について話し合います。
-
- 平均二乗誤差(Mean Square Error)
-
- 平方根平均二乗誤差(Root Mean Square Error)
-
- 平均絶対誤差(Mean Absolute Error)
- クロスエントロピー損失(Cross-Entropy Loss)
これらの4つの損失関数のうち、最初の3つは回帰に適用可能であり、最後の1つは分類モデルの場合に適用可能です。
Pythonで損失関数を実装する
これらの損失関数をPythonで実装する方法を見てみましょう。
1. 平均二乗誤差(MSE)
平均二乗誤差(MSE)は、予測値と実際の観測値の差の2乗の平均として計算されます。数学的には、以下のように表現することができます。
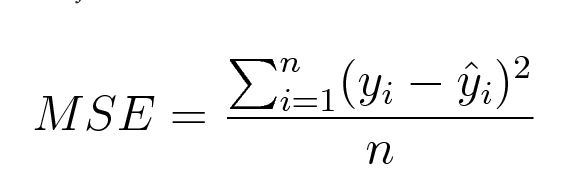
MSEのPythonの実装は以下のようになります:
import numpy as np
def mean_squared_error(act, pred):
diff = pred - act
differences_squared = diff ** 2
mean_diff = differences_squared.mean()
return mean_diff
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
print(mean_squared_error(act,pred))
出力:
0.04666666666666667
sklearnのmean_squared_errorも使って、MSEを計算することもできます。以下にその関数の使い方を示します。
from sklearn.metrics import mean_squared_error
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_squared_error(act, pred)
結果:
0.04666666666666667
2. ルート平均二乗誤差 (RMSE)
平方平均二乗誤差(RMSE)は、平均二乗誤差の平方根で計算されます。数学的には、以下のように表現できます。
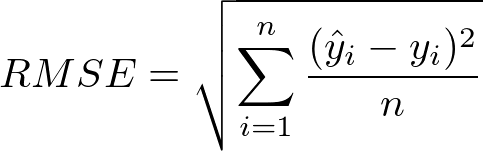
RMSEのPython実装は次のようになります。
import numpy as np
def root_mean_squared_error(act, pred):
diff = pred - act
differences_squared = diff ** 2
mean_diff = differences_squared.mean()
rmse_val = np.sqrt(mean_diff)
return rmse_val
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
print(root_mean_squared_error(act,pred))
出力:
0.21602468994692867
「mean_squared_error」を使用して、RMSEを計算することもできます。同じ関数を使用して、RMSEを実装する方法を見てみましょう。
from sklearn.metrics import mean_squared_error
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_squared_error(act, pred, squared = False)
出力:
0.21602468994692867
もしパラメーター「squared」がTrueに設定されている場合、関数はMSEの値を返します。Falseに設定されている場合、関数はRMSEの値を返します。
3. 平均絶対誤差(MAE)
Mean Absolute Error (MAE)は、予測値と実際の観測値の絶対値の差の平均として計算されます。数学的には、以下のように表現できます。
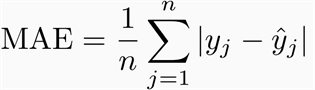
MAEのPython実装は以下の通りです:
import numpy as np
def mean_absolute_error(act, pred):
diff = pred - act
abs_diff = np.absolute(diff)
mean_diff = abs_diff.mean()
return mean_diff
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_absolute_error(act,pred)
出力:
0.20000000000000004
あなたはsklearnのmean_absolute_errorも使用してMAEを計算することもできます。
from sklearn.metrics import mean_absolute_error
act = np.array([1.1,2,1.7])
pred = np.array([1,1.7,1.5])
mean_absolute_error(act, pred)
出力:
0.20000000000000004
Pythonでのクロスエントロピー損失関数
クロスエントロピー損失は、ネガティブ対数尤度とも称されています。これは、主に分類問題で使用されます。分類問題とは、例を2つ以上のクラスのいずれかに分類する問題です。
バイナリ分類問題の場合、エラーの計算方法について見てみましょう。
犬と猫の区別をしようとするモデルを考えてみましょう。
以下はエラーを見つけるためのPythonのコードです。
from sklearn.metrics import log_loss
log_loss(["Dog", "Cat", "Cat", "Dog"],[[.1, .9], [.9, .1], [.8, .2], [.35, .65]])
出力:
出力結果:
0.21616187468057912
私たちは、scikit-learnのlog_lossメソッドを使用しています。
関数の呼び出し時の最初の引数は、各入力に対する正しいクラスラベルのリストです。2番目の引数は、モデルによって予測された確率のリストです。
確率は以下の形式で表示されます。
[P(dog), P(cat)]
結論
このチュートリアルは、Pythonでの損失関数についてでした。回帰および分類の問題に対してさまざまな損失関数をカバーしました。私たちと一緒に学ぶことが楽しかったと願っています!

