RプログラミングでROCカーブをプロットする。
皆さん、こんにちは!この記事では、機械学習の重要なエラーメトリックであるROC曲線のRプログラミングにおけるプロットの詳細を取り上げます。
それでは、始めましょう!! (Sorede wa, hajimemashou!)
ROC曲線の必要性
エラーメトリクスは、特定のデータセットでモデルの機能を評価し正当化することができます。
ROCプロットはそのようなエラーメトリックスの一つです。
ROCプロット、またはROC AUCカーブとしても知られるものは、分類の誤りメトリックです。つまり、分類の機能と結果を評価するための機械学習アルゴリズムの評価指標です。
正確に言うと、ROC曲線は値の確率曲線を表し、AUCは異なるグループの値/ラベルの分離度を測るものです。ROC AUC曲線を使用することで、モデルがラベルに基づいて正しく識別・分類した値の量を分析し、結論を導くことができます。
AUCスコアが高ければ、予測された値の分類がより優れています。
例えば、投げたコインの結果が「表」か「裏」かを予測し分類するためのモデルを考えてみましょう。
したがって、AUCスコアが高い場合、モデルは『表』を『表』として、『裏』を『裏』としてより効率的に分類する能力があることを示しています。
技術的な観点から言えば、ROC曲線はモデルの真陽性率と偽陽性率の間にプロットされる。
では、次のセクションでROC曲線の概念を実装してみましょう!
メソッドI:plot()関数を使用
以前にも話したように、ROCプロットを使用して機械学習モデルを評価することができます。ですので、ロジスティック回帰モデルに対してROCカーブの概念を実装してみましょう。
始めましょう!:)
この例では、ロジスティック回帰を用いて、銀行の貸し倒れデータセットをモデリングします。その後、’pROC’ライブラリのplot()関数を使用してROC曲線をプロットします。データセットはこちらで入手できます!
-
- 最初に、read.csv()関数を使用してデータセットを環境に読み込みます。
-
- モデリングの前に、データセットの分割は重要なステップです。そのため、RのドキュメントからcreateDataPartition()関数を使用してデータセットをトレーニングデータとテストデータにサンプル化します。
-
- モデルの機能を評価するために、我々は特定のエラーメトリクスを設定しています。これには、精度、再現率、正解率、F1スコア、ROCプロットなどが含まれます。
-
- 最後に、Rのglm()関数を使用してデータセットにロジスティック回帰を適用します。さらに、テストデータ上のモデルをpredict()関数を使用してテストし、エラーメトリクスの値を得ます。
- 最後に、roc()メソッドを使用してモデルのROC AUCスコアを計算し、同じ値を’pROC’ライブラリで利用可能なplot()関数を使用してプロットします。
rm(list = ls())
#Setting the working directory
setwd("D:/Edwisor_Project - Loan_Defaulter/")
getwd()
#Load the dataset
dta = read.csv("bank-loan.csv",header=TRUE)
### Data SAMPLING ####
library(caret)
set.seed(101)
split = createDataPartition(data$default, p = 0.80, list = FALSE)
train_data = data[split,]
test_data = data[-split,]
#error metrics -- Confusion Matrix
err_metric=function(CM)
{
TN =CM[1,1]
TP =CM[2,2]
FP =CM[1,2]
FN =CM[2,1]
precision =(TP)/(TP+FP)
recall_score =(FP)/(FP+TN)
f1_score=2*((precision*recall_score)/(precision+recall_score))
accuracy_model =(TP+TN)/(TP+TN+FP+FN)
False_positive_rate =(FP)/(FP+TN)
False_negative_rate =(FN)/(FN+TP)
print(paste("Precision value of the model: ",round(precision,2)))
print(paste("Accuracy of the model: ",round(accuracy_model,2)))
print(paste("Recall value of the model: ",round(recall_score,2)))
print(paste("False Positive rate of the model: ",round(False_positive_rate,2)))
print(paste("False Negative rate of the model: ",round(False_negative_rate,2)))
print(paste("f1 score of the model: ",round(f1_score,2)))
}
# 1. Logistic regression
logit_m =glm(formula = default~. ,data =train_data ,family='binomial')
summary(logit_m)
logit_P = predict(logit_m , newdata = test_data[-13] ,type = 'response' )
logit_P <- ifelse(logit_P > 0.5,1,0) # Probability check
CM= table(test_data[,13] , logit_P)
print(CM)
err_metric(CM)
#ROC-curve using pROC library
library(pROC)
roc_score=roc(test_data[,13], logit_P) #AUC score
plot(roc_score ,main ="ROC curve -- Logistic Regression ")
出力されるもの:
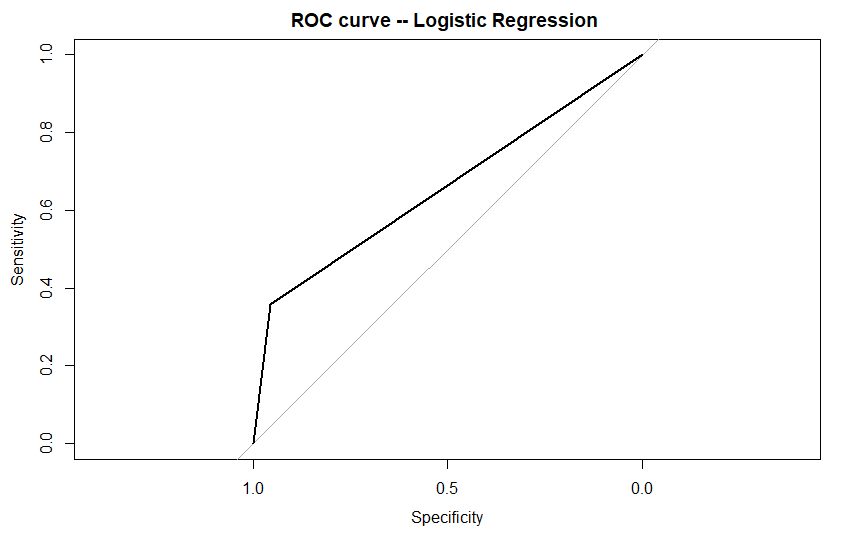
メソッドII: roc.plot()関数を使用する方法
Rプログラミングには、モデルのROC-AUC曲線をプロットするための別のライブラリーとして「verification」というものがあります。
機能を活用するためには、環境に「verification」ライブラリをインストールしてインポートする必要があります。
これを行った後、次のようにしてデータの評価を明確にするために、roc.plot()関数を使用してデータをプロットします。これにより、「感度」と「特異度」のデータ値の間の比較が可能となります。
install.packages("verification")
library(verification)
x<- c(0,0,0,1,1,1)
y<- c(.7, .7, 0, 1,5,.6)
data<-data.frame(x,y)
names(data)<-c("yes","no")
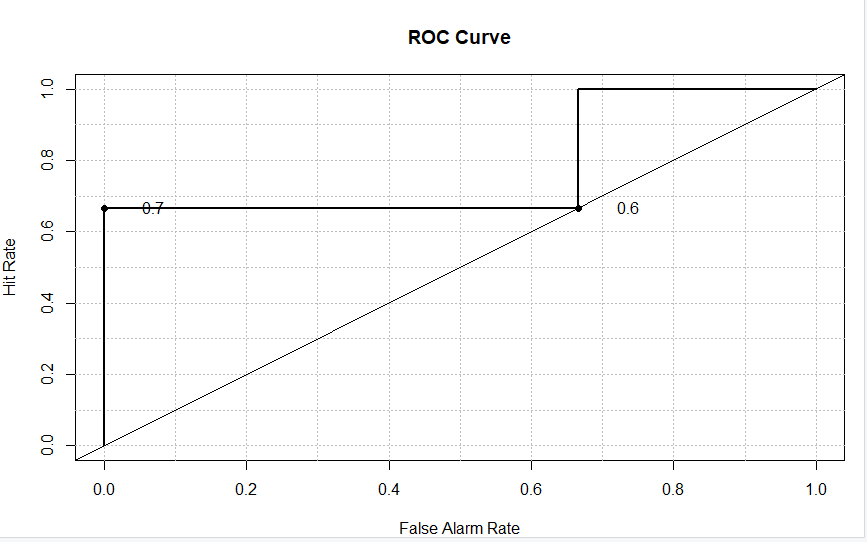
roc.plot(data$yes, data$no)
以下を日本語で自然に言い換えてください。1つの選択肢で結構です。
結果:
結論
これによって、このトピックは終わりになりました。もし質問があれば、どんなことでも下にコメントしてください。
他の機械学習モデルでもROCプロットの概念を実装してみてください。そして、コメントセクションで理解を教えてください。
それまで、お楽しみにして、楽しい学びをしていてください!

