Rプログラミングのunique()関数
Rのunique()関数は、ベクトル、データフレーム、または行列に存在する重複した値や行を削除するために使用されます。
unique()関数は、探索的データ分析(EDA)において重要性が見出されており、データ内の重複値を直接的に特定し、削除する役割を果たします。
この記事では、Rプログラミングのunique()関数のさまざまな応用を紹介します。いざスタートです!
ユニークな値を得るというアイデア
それでは、話題に入る前に、その背後にあるアイデアを知ることが良いです。この場合、それはユニークな値です。ユニークな関数は、重複したカウントを排除してユニークな値を返します。
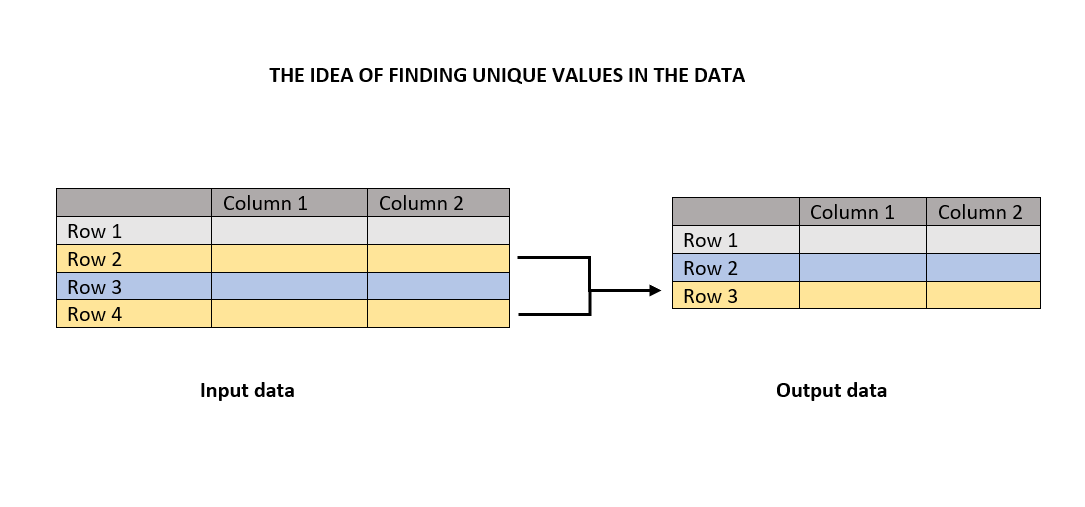
図は、ユニークな関数が重複を検索し、それを排除してユニークな値を返すことを示しています。次のセクションでは、良いことを教えるために多くのイラストが用意されています。
RにおけるUnique()関数の構文
ユニーク: unique()関数は、データ内に存在する重複カウントを特定し、除去するために使用されます。
unique(x)
どこで:
Xはベクトル、データフレーム、または行列のいずれかです。
R での unique() 関数のシンプルな例
ベクトルに重複した値がある場合、unique() 関数の使用により、たった一行のコードで簡単にそれらを除去することができます。
どういう風に機能するか見てみましょう。 (Dou iu fuu ni kinou suru ka mite mimashou.)
#An input vector having duplicate values
df<-c(1,2,3,2,4,5,1,6,8,9,8,6)
#elimnates the duplicate values in the vector
unique(df)
Output = 1 2 3 4 5 6 8 9
上のイラストでは、入力ベクトルには多くの重複した値があることが分かります。
上記のように、私たちがそのベクトルをユニークな関数に渡すと、重複した値はすべて取り除かれ、ユニークな値のみが返されます。
行列内の一意の値を見つける
今、私たちは行列に存在する重複した値を見つけ、ユニークな関数を使用してそれらを削除する予定です。
これには、まず重複する値を持つ「n」行と列の行列を作成する必要があります。
以下のコードを実行して、行列を作成します。
#creates a 6 x 4 matrix having 24 elements
df<-matrix(rep(1:20,length.out=24),nrow = 6,ncol=4,byrow = T)
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
[4,] 13 14 15 16
[5,] 17 18 19 20
[6,] 1 2 3 4
簡単に気づけるように、最後の行が完全に重複していることが分かります。unique()関数を使って、これらの重複した値を削除するだけで済みます。
#removes the duplicate values
unique(df)
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
[4,] 13 14 15 16
[5,] 17 18 19 20
やった!
やったね!行列内の重複した値は、ユニークな関数によって削除され、ユニークな値だけを含む行列が返されました。
データフレーム内のユニークな値を見つける
今まで、私たちはベクトルと行列に取り組んで、重複した数を削除し、一意の値を抽出する作業を行いました。
このセクションでは、データフレームに存在する一意の値に焦点を当てましょう。
データフレームを作成するには、以下のコードを実行します。
#creates a data frame
> Class_data<-data.frame(Student=c('Naman','Megh','Mark','Naman','Megh','Mark'),Age=c(22,23,24,22,23,24),Gender=c('Male','Female','Male','Male','Female','Male'))
#dataframe
Class_data
Student Age Gender
1 Naman 22 Male
2 Megh 23 Female
3 Mark 24 Male
4 Naman 22 Male
5 Megh 23 Female
6 Mark 24 Male
上記に示す重複数を持つデータフレームです。ここにある重複値を取り除くために、ユニーク関数を適用しましょう。
unique(Class_data)
Student Age Gender
1 Naman 22 Male
2 Megh 23 Female
3 Mark 24 Male
わあ!ユニークな機能は、重複した値を排除して、データフレームに存在するすべてのユニークな値を返しました。
ただこんな風に、Rのunique()関数を使えば、データに含まれるユニークな値を簡単に取得することができます。
特定の列のユニークな値を見つけること
特定の列ではなく、データセットから一意の値を取得する必要がある場合、どうしますか?
心配しないで、unique()関数を使用することで、以下のように特定の列から一意の値も取得できます。
#creates a data frame
> Class_data<-data.frame(Student=c('Naman','Megh','Mark','Naman','Megh','Mark'),Age=c(22,23,24,22,23,24),Gender=c('Male','Female','Male','Male','Female','Male'))
#dataframe
Class_data
Student Age Gender
1 Naman 22 Male
2 Megh 23 Female
3 Mark 24 Male
4 Naman 22 Male
5 Megh 23 Female
6 Mark 24 Male
はい、簡単な理解のために前のセクションで使用したデータフレームと同じものを使用しています。
「重複した値を排除するために、ユニークな機能を使用しましょう。」
unique(Class_data$Student)
Output = "Naman" "Megh" "Mark"
同様に、AgeやGenderの列でもユニークな値を取得することができます。
unique(Class_data$Gender)
"Male" "Female"
ユニークな値の長さを求める。
このセクションでは、データのユニークな値の数を取得します。このアプリケーションは、データをよりよく理解し、さらなる分析のために準備するために役立ちます。
#importing the dataset
datasets::BOD
Time demand
1 1 8.3
2 2 10.3
3 3 19.0
4 4 16.0
5 5 15.6
6 7 19.8
ええと、ここではBODデータセットを使用しています。まずは、ユニークな値を見つけて、その後にその数を数えましょう。
#returns the unique value
unique(BOD$demand)
Output = 8.3 10.3 19.0 16.0 15.6 19.8
では、BODデータセットの需要列に存在するユニークな値があります。
今、ユニークな値の数を探すために準備が整いました。
#returns the length of unique values
length(unique(BOD$demand))
Output = 6
締めくくる (Shimekukuru)
ええ、Rのunique()関数は、探索的データ分析(EDA)において非常に貴重なものです。
データの理解を深めるのに役立ち、特定のカウントも提供します。
この記事は、unique() 関数の複数の応用と使用例について説明しています。分析を楽しんでください!
もっと読む:Rのドキュメンテーション

