Rで標準偏差を計算する方法は?
統計言語として、Rは値の標準偏差を求めるための標準関数sd(’ ‘)を提供しています。
では、標準偏差とは何ですか? (De wa, hyōjun henka to wa nandesu ka?)
- ‘Standard deviation is the measure of the dispersion of the values’.
- The higher the standard deviation, the wider the spread of values.
- The lower the standard deviation, the narrower the spread of values.
- In simple words the formula is defined as – Standard deviation is the square root of the ‘variance’.
標準偏差の重要性
標準偏差は統計学において非常に人気がありますが、なぜでしょうか?その人気や重要性の理由を以下に挙げます。
- Standard deviation converts the negative number to a positive number by squaring it.
- It shows the larger deviations so that you can particularly look over them.
- It shows the central tendency, which is a very useful function in the analysis.
- It has a major role to play in finance, business, analysis, and measurements.
話題に入る前に、この定義を心に留めておいてください!
分散(ぶんさん)- 観測値と期待値の二乗差として定義されます。
リスト内の値の標準偏差をRで求めます。
この方法では、リスト「x」を作成し、それにいくつかの値を追加します。そして、そのリスト内の値の標準偏差を求めることができます。
x <- c(34,56,87,65,34,56,89) #creates list 'x' with some values in it.
sd(x) #calculates the standard deviation of the values in the list 'x'
出力は22.28175です。
今、標準偏差を求めるためにリスト「y」から特定の値を抽出してみることができます。
y <- c(34,65,78,96,56,78,54,57,89) #creates a list 'y' having some values
data1 <- y[1:5] #extract specific values using its Index
sd(data1) #calculates the standard deviation for Indexed or extracted values from the list.
出力:23.28519
CSVファイルに保存された値の標準偏差を求める。
この方法では、CSVファイルをインポートして、そのファイルに格納されている値のRにおける標準偏差を求めています。
readfile <- read.csv('testdata1.csv') #reading a csv file
data2 <- readfile$Values #getting values stored in the header 'Values'
sd(data2) #calculates the standard deviation
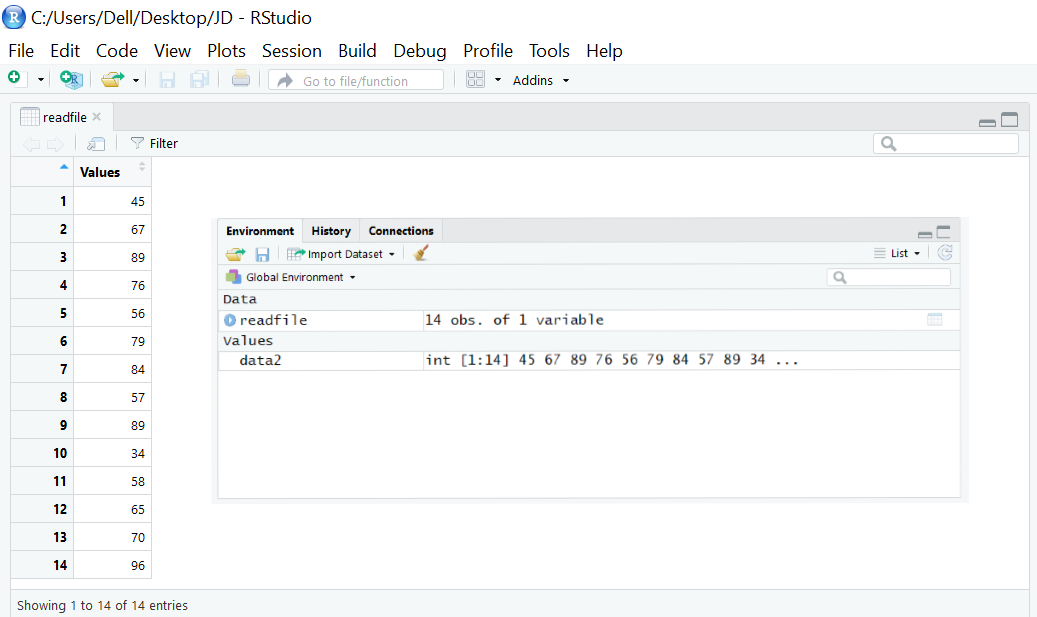
出力 -〉17.88624
高い標準偏差
一般的に、標準偏差が低い場合は値は平均値に非常に近くなり、標準偏差が高い場合は値は平均値から広がります。
このことを例を挙げて説明することができます。 (Kono koto o rei o agete setsumei suru koto ga dekimasu.)
x <- c(79,82,84,96,98)
mean(x)
---> 82.22222
sd(x)
---> 10.58038
Rを使用してこれらの値を棒グラフにプロットするには、以下のコードを実行します。
ggplot2パッケージをインストールするためには、Rスタジオでこのコードを実行してください。
「ggplot2」をインストールするために、次のコマンドを実行してください: install.packages(“ggplot2”)。
library(ggplot2)
values <- data.frame(marks=c(79,82,84,96,98), students=c(0,1,2,3,4,))
head(values) #displayes the values
marks students
1 79 0
2 82 1
3 84 2
4 96 3
5 98 4
x <- ggplot(values, aes(x=marks, y=students))+geom_bar(stat='identity')
x #displays the plot
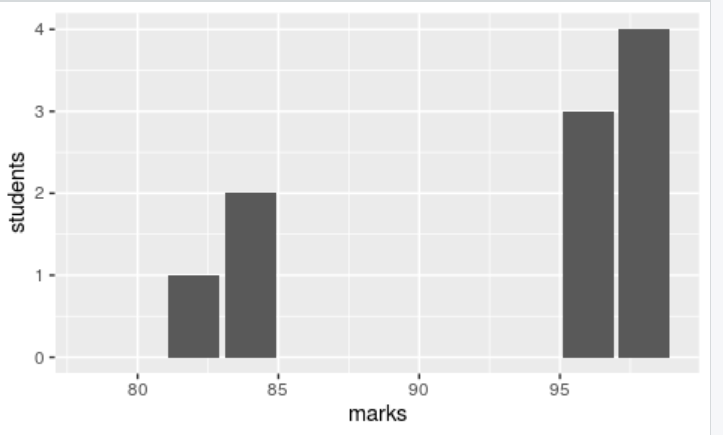
上記の結果では、データのほとんどが平均値(79、82、84)の周囲にクラスタリングされており、標準偏差が低いことがわかります。
高標準偏差を示すイラスト。
y <- c(23,27,30,35,55,76,79,82,84,94,96)
mean(y)
---> 61.90909
sd(y)
---> 28.45507
以下のコードを実行して、Rのggplotでこれらの値を棒グラフとしてプロットしてください。
library(ggplot2)
values <- data.frame(marks=c(23,27,30,35,55,76,79,82,84,94,96), students=c(0,1,2,3,4,5,6,7,8,9,10))
head(values) #displayes the values
marks students
1 23 0
2 27 1
3 30 2
4 35 3
5 55 4
6 76 5
x <- ggplot(values, aes(x=marks, y=students))+geom_bar(stat='identity')
x #displays the plot
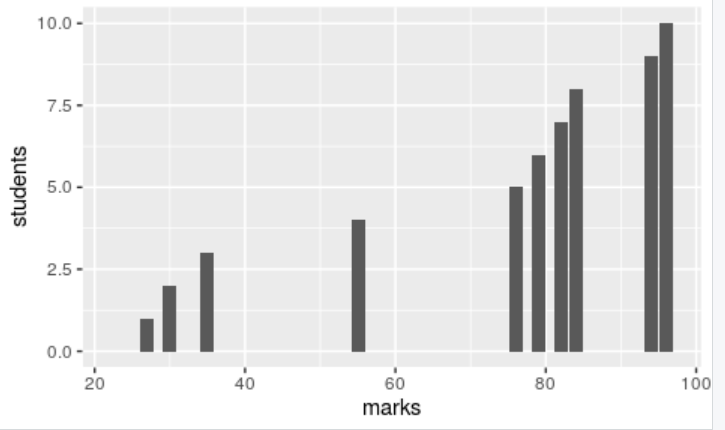
上記の結果では、広範囲なデータが見られます。平均点61からはるかに離れた最低点23が見られます。これは高い標準偏差と呼ばれています。
今までに、R言語のsd(’ ‘)関数を使用して標準偏差を計算する方法について十分に理解ができたでしょう。このチュートリアルをまとめるために、簡単な問題を解決してみましょう。
例1:偶数のリストの標準偏差
1から20(1と20は除く)の偶数の標準偏差を求めてください。
解決策: 1から20までの偶数は以下の通りです。
2、4、6、8、10、12、14、16、18
これらの値の標準偏差を求めましょう。
x <- c(2,4,6,8,10,12,14,16,18) #list of even numbers from 1 to 20
sd(x) #calculates the standard deviation of these
values in the list of even numbers from 1 to 20
出力は5.477226です。
例えば、アメリカの人口データの標準偏差。
アメリカの州ごとの人口の標準偏差を求めてください。
これに関しては、CSVファイルをインポートして値を読み込み、標準偏差を求めてRで結果をヒストグラムにプロットします。
df<-read.csv("population.csv") #reads csv file
data<-df$X2018.Population #extarcts the data from population
column
mean(data) #calculates the mean
View(df) #displays the data
sd(data) #calculates the standard deviation
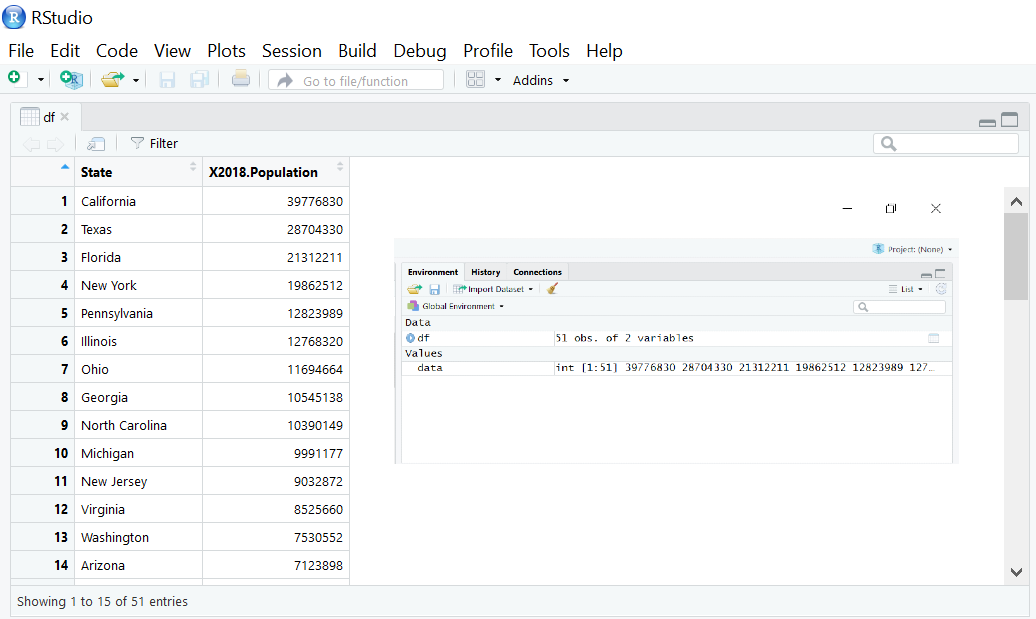
出力 —-> 平均 = 6432008、標準偏差 = 7376752
結論
Rの値の標準偏差を求めるのは簡単です。Rには標準偏差を求めるためのsd(’ ‘)という標準関数があります。標準偏差を求めるためには、値のリストを作成するか、CSVファイルをインポートすることができます。
重要:上記のようにインデックスを使用してファイルやリストから一部の値を抽出し、標準偏差を計算することを忘れないでください。
質問箱を使用して、Rのsd(’ ‘)関数に関する疑問を投稿してください。楽しい学びを!

