RにおけるQuantile()関数 – 簡単なガイド
Rのquantile()関数を使用することで、サンプルの分位点を生成することができます。
皆さん、こんにちは。今日は、quantile()関数を使って値の分位数を求める方法について見ていきます。
分位数(Quantile)とは、素人にもわかりやすく言えば、等しいグループやサイズに分割されたサンプルのことです。この特性により、分位数はフラクタイル(Fractiles)とも呼ばれます。分位数では、25パーセンタイルは下位四分位数と呼ばれ、50パーセンタイルは中央値と呼ばれ、75パーセンタイルは上位四分位数と呼ばれます。
以下のセクションでは、Rでのquantile()関数の動作を見てみましょう。
Quantile()関数の構文
RのQuantile()関数の構文
quantile(x, probs = , na.rm = FALSE)
「どこで」 (Doko de)
- X = the input vector or the values
- Probs = probabilities of values between 0 and 1.
- na.rm = removes the NA values.
Rでのquantile()関数の簡単な実装
よく、分位数関数に関する定義と説明について理解していることを願っています。さて、Rで分位数関数がどのように機能するかを、入力データの分位数を返すシンプルな例を使って見てみましょう。
#creates a vector having some values and the quantile function will return the percentiles for the data.
df<-c(12,3,4,56,78,18,46,78,100)
quantile(df)
出力:
0% 25% 50% 75% 100%
3 12 46 78 100
上記のサンプルでは、分位数関数がまず入力値を昇順に並べ、その後、必要なパーセンタイルの値を返します。
注意:分位数関数はデータを等しい半分に分割し、その中央値が中央として機能し、その上の残りの下部が下位四分位数であり、上部が上位四分位数です。
欠損値を処理する – ‘NaN’に対処する
あちこちにNaNは存在します。このデータ駆動型のデジタル世界では、これらのNaNに頻繁に遭遇することがあります。これらはしばしば欠損値と呼ばれます。もしデータに欠損値がある場合、出力にNaNが表示されたり、出力にエラーが発生する可能性があります。
したがって、これらの欠損値を処理するために、na.rm関数を使用します。この関数は、データからNA値を削除し、正しい値を返します。
これがどのように機能するか見てみましょう。
#creates a vector having values along with NaN's
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
quantile(df)
出力:
Error in quantile.default(df) :
missing values and NaN's not allowed if 'na.rm' is FALSE
ああ、エラーが発生しましたね。もし、あなたの予測がNAの値に関連しているのであれば、あなたは完全に正しいです。もし私たちのデータにNAの値が含まれている場合、ほとんどの関数はNAの値そのもの、または上記に述べられたエラーメッセージを返します。
では、na.rm関数を使ってこれらの欠損値を取り除きましょう。
#creates a vector having values along with NaN's
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
#removes the NA values and returns the percentiles
quantile(df,na.rm = TRUE)
出力:
0% 25% 50% 75% 100%
3 12 46 78 100
上記のサンプルでは、na.rm関数とその出力に与える影響が見られます。この関数は、誤った出力を避けるためにNAを削除します。
quantileの ‘Probs’ 引数
最初のセクションで紹介された構文の”probs”引数を見ると、それが意味するものやどのように機能するのか疑問に思うかもしれません。”probs”引数は、特定のパーセンタイルやカスタムパーセンタイルを取得するために、quantile関数に渡されます。
複雑そうですか?心配しないでください、私がわかりやすく説明します。 (Fukuzatsu sō desu ka? Shinpai shinaide kudasai, watashi ga wakariyasuku setsumei shimasu.)
関数quantileを使用すると、標準的なパーセンタイル(25、50、75パーセンタイルなど)が返されますが、もしも47パーセンタイルや88パーセンタイルが必要な場合はどうすればいいですか?
そこには「確率」という議論があります。それにより、必要なパーセンタイルを指定することができます。
例に入る前に、probs引数についていくつかのことを知っておく必要があります。
問題点:「probs」または「probabilities(確率)」の引数は、0から1の間にあるべきです。
上記の文を示すサンプルがあります。
#creates the vector of values
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
#returns the quantile of 22 and 77 th percentiles.
quantile(df,na.rm = T,probs = c(22,77))
出力:
Error in quantile.default(df, na.rm = T, probs = c(22, 77)) :
'probs' outside [0,1]
ああ、エラーだ! (Aa, erā da!)
「起こったことについて、アイデアをつかみましたか?」
さて、ここにProbsステートメントが来ました。Probsの引数で正しい値を指定したにもかかわらず、0から1の条件に違反します。Probsの引数には0から1の範囲にあるべき値を含める必要があります。
だから、私たちは22番と77番の確率を0.22と0.77に変換しなければなりません。今、入力値は0から1の間にあるんですよね?これが理解できればいいのですが。
#creates a vector of values
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
#returns the 22 and 77th percentiles of the input values
quantile(df,na.rm = T,probs = c(0.22,0.77))
出力:
22% 77%
10.08 78.00
「Unname」機能とその使用
コードがパーセンタイルのみを返し、カットポイントを避けたい場合、’unname’関数を利用することができます。
「unname」関数は、見出しまたは切断点(0%、25%、50%、75%、100%)を削除し、パーセンタイルのみを返します。
どうやって動くか見てみましょう! (Dou yatte ugoku ka mite mimashou!)
#creates a vector of values
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
quantile(df,na.rm = T,probs = c(0.22,0.77))
#avoids the cut-points and returns only the percentiles.
unname(quantile(df,na.rm = T,probs = c(0.22,0.77)))
出力:
10.08 78.00
今では、カットポイントは非活性化または削除され、パーセンタイルのみが返されることが観察できます。
‘round’(丸める)関数とその使用
過去の記事で、私たちはRのround関数について詳しく話し合いました。今度は、そのround関数を使って値を四捨五入する予定です。
どのように機能するか見てみましょう!(Dō no yō ni kinō suru ka mite mimashō!)
#creates a vector of values
df<-c(12,3,4,56,78,18,NA,46,78,100,NA)
quantile(df,na.rm = T,probs = c(0.22,0.77))
#returns the round off values
unname(round(quantile(df,na.rm = T,probs = c(0.22,0.77))))
出力:
10 78
私たちの出力値は小数点以下を切り捨てていることがわかります。
データセットの複数のグループ/列について分位点を取得してください。
ここまでは、分位点関数について、その使い方や応用、引数についてお話ししてきました。それらの正しい使い方についても説明しました。
このセクションでは、データセット内の複数の列の分位点を取得します。面白いですか?私についてきてください!
この目的のために、私は「mtcars」というデータセットを使用し、また「dplyr」ライブラリを使います。
#reads the data
data("mtcars")
#returns the top few rows of the data
head(mtcars)
#install required paclages
install.packages('dplyr')
library(dplyr)
#using tapply, we can apply the function to multiple groups
do.call("rbind",tapply(mtcars$mpg, mtcars$gear, quantile))
出力:
0% 25% 50% 75% 100%
3 10.4 14.5 15.5 18.400 21.5
4 17.8 21.0 22.8 28.075 33.9
5 15.0 15.8 19.7 26.000 30.4
上記のプロセスでは、まず「dplyr」パッケージをインストールする必要があります。その後、tapply関数とrbind関数を使用して、mtcarsデータセットの複数の列を取得します。
上記のセクションでは、mtcarsデータセットの「mpg」や「gear」などの複数の列を取り上げました。このように、データセット内の複数のグループに対して四分位数を計算することができます。
パーセンタイルを視覚化できますか?
日本語での表現例:
私の回答は「はい」という大きなものです!これに最適なプロットはボックスプロットです。アヤメのデータセットを使って、パーセンタイルも表示されるボックスプロットを作成してみましょう。
行こう!(いこう!)
data(iris)
head(iris)
これは、最初の6つのバリューを持つアヤメのデータセットです。
「Summary」という関数を使って、データを探索しましょう。
summary(iris)
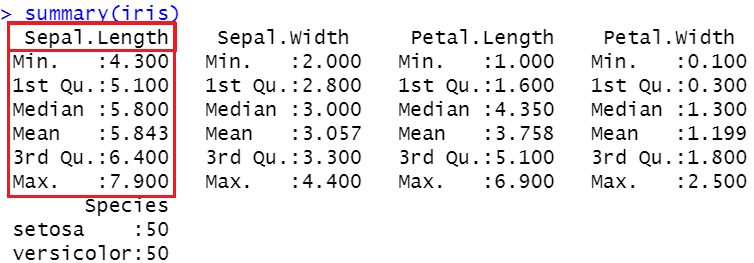
上の画像では、平均値、中央値、第25パーセンタイル(第1四分位数)、第75パーセンタイル(第3四分位数)、最小値、最大値が見えます。この情報をボックスプロットでプロットしましょう。
やろう!
#plots a boxplot with labels
boxplot(iris$Sepal.Length,main='The boxplot showing the percentiles',col='Orange',ylab='Values',xlab='Sepal Length',border = 'brown',horizontal = T)
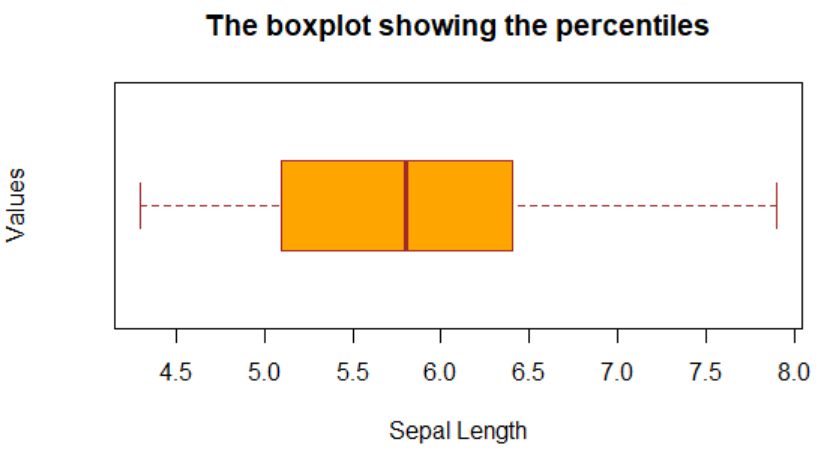
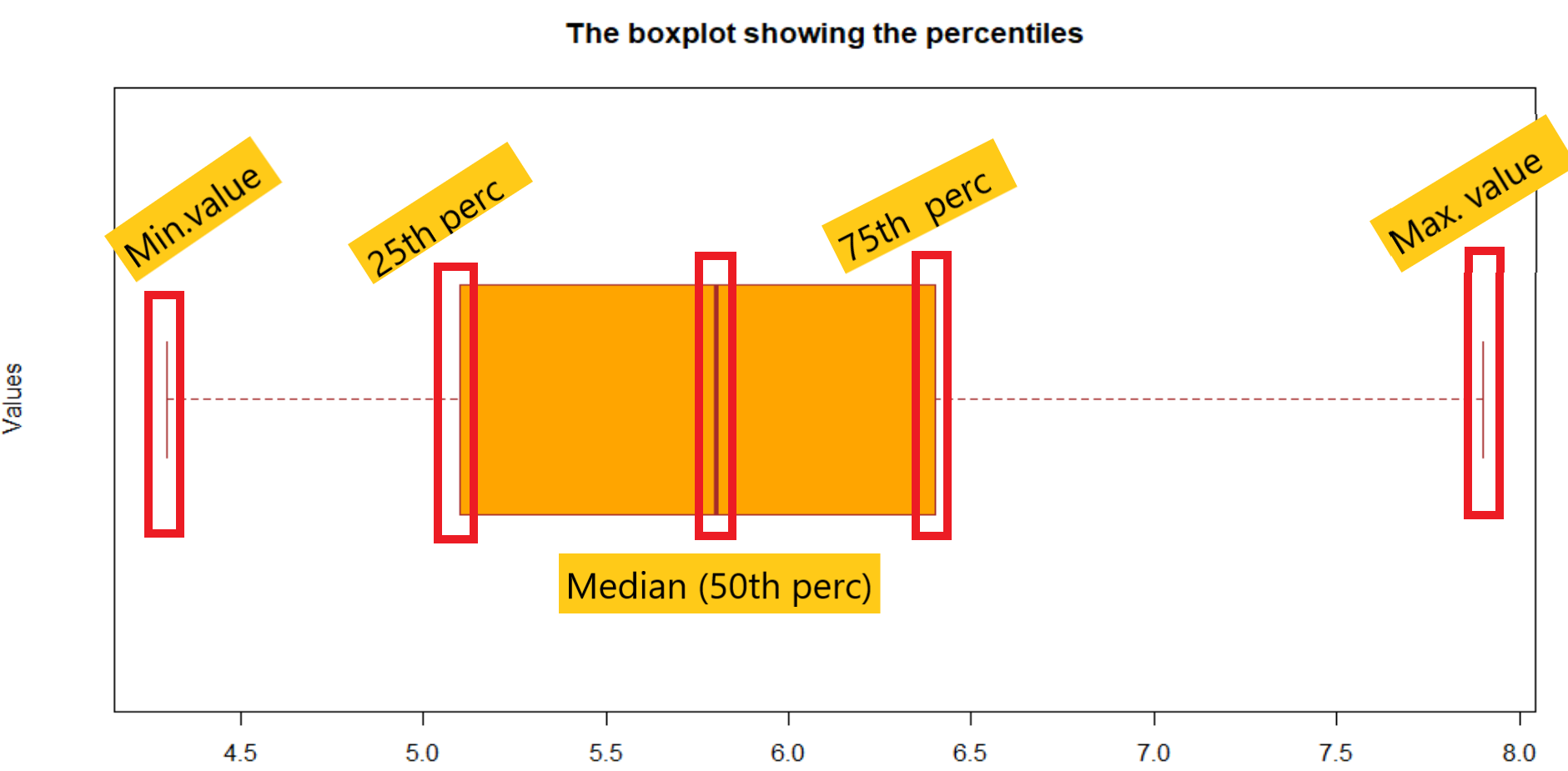
箱ひげ図はデータの多くの側面を示すことができます。以下の図には、箱ひげ図で表される特定の値を記載しました。これにより、時間を節約しながら最も理解しやすくなるように支援します。
RでのQuantile()関数 – まとめ
まあ、考えてみるとそれは長めの記事ですね。そして、私はquantile()関数について、さまざまな例やイラストを通じて、複数の次元で説明し探求するために最善を尽くしました。quantile関数は、与えられたデータについてより多くの情報を効率的に明らかにするため、データ分析で最も有用な関数です。
「quantile()関数についてのブズがよく理解できたと思います。今回はこれで終わりです。これからもRプログラミングに関する美しい関数やトピックを提供していきますので、それまでお気をつけてデータ分析を楽しんでください!!!」
もっと勉強しましょう:Rのドキュメンテーション。

