デジタルオーシャンのvServer上でCPU使用状況をモニタリングする方法
はじめに
あなたのウェブサイトやアプリが通常よりも遅い場合、問題の原因を調査する方法はどうすれば良いですか? 遅いアプリケーションの原因はさまざまですが、時にはサーバーのCPUが最大限に使用されているためです。 このガイドにより、あなたがそのような状況になっているかどうか判断することができます。
まず、Linuxサーバーで最もよく参照されるリソース使用の2つのメトリックであるCPU利用率と負荷平均を理解することから始めましょう。これら2つのメトリックの違いを探り、uptimeとtopという2つのコマンドラインユーティリティを使用してその値をチェックする方法についてご紹介します。最後に、Silicon Cloud Monitoringを使用してこれらのメトリックを時間経過で追跡し、通常の値を上回ったときにはメールやSlackで通知するアラーティングポリシーを設定する方法について説明します。
必要条件
このガイドに従うには、以下が必要です:
- A two-core Silicon Cloud vServer with Monitoring enabled. Read our documentation if you don’t know how to create a vServer. Also read the guide How To Install the Silicon Cloud Metrics Agent to learn how to enable Monitoring on your new vServer or add the Monitoring Agent to an existing vServer.
- The stress utility installed on your vServer. Use apt or dnf to install stress from your distribution’s repositories.
このガイドにおいて紹介されている、uptime と top という2つのコマンドラインユーティリティは、ほとんどの Linux ディストリビューションにデフォルトで含まれています。
背景
CPU利用率と平均負荷を確認および追跡する方法を見る前に、概念的に考えてみましょう。それらは何を測定しているのでしょうか?
CPUの利用率と負荷平均
これらの2つの頻繁にチェックされるメトリックは、どちらもCPUに関係があり、サーバーが負荷過多のように見える場合にはどちらも高いことがありますが、同じものを計測しているわけではなく、必ずしも直接的に関連付けられるわけではありません。CPU利用率は現在CPUがどれだけ忙しいかを示し、ロード平均は直近の過去の平均で、CPU上で待っているタスクの数や実行中のタスクの数を示します。
Note
サーバーのCPUをスーパーマーケットのレジ係と考えると、タスクは顧客となります。CPUの負荷は、レジに配されている顧客を含む列にいる総人数のカウントです。CPUの利用率は、レジ係がどれだけ効率的に働いているかを示します。
もちろん、これらの2つの指標には関連があります。レジ待ちの行が長くなる明らかな理由の1つは、店舗のレジ係が遅すぎる(または少なすぎる)場合です。しかし、行が詰まる原因は他にもあります。顧客が商品の価格チェックを依頼した場合、レジ係は他の従業員に依頼します。レジ係は価格チェックを待っている間に他の商品をスキャンし続けるかもしれませんが、他の商品がスキャンされている間にチェックが戻ってこない場合(価格チェッカーが一時的に離席しているかもしれない)、レジ係と顧客は待っている間に行が長くなってしまいます。これは、遅いまたは利用できないI/Oデバイス(つまり、ディスク)を待つタスクに似ており、実際にはI/O負荷が重いワークロードは負荷平均は高くなるがCPU利用率は低くなる可能性があります。
今、30分間の昼休みでプライスチェッカーがいなくなったと想像してください。その間に、さらに数人の顧客がプライスチェックが必要です。(アイドルなキャッシャー自体は、ディスクの機能を実行できないように、プライスチェックも行うことはできません。)キャッシャーはこれらの顧客を横に置いて、残りの顧客を取り組み、会計列を空にします。キャッシャーは現在、アイドル(利用率0%)ですが、まだ彼女の時間が必要ないくつかの顧客(非ゼロの負荷)が立ち回っています。ただし、プライスチェッカーが戻ってくるのを待っているため、彼らの会計を完了することはできません。キャッシャーを必要とする需要はありますが、彼女は忙しくありません。そのため、新しい顧客がレジに接近すると、すぐに対応されます。
おそらく、他の食料品店の問題を想像することができるでしょう。それによって、キャッシャーの責任ではないにもかかわらず待ち時間が長くなることがあります。しかし、それについて考えると、CPU使用率、負荷平均値、I/O待機時間、CPUスケジューリングについてより詳細な議論が展開されます。このガイドの範囲外の議論なので、今のところは以下を覚えておいてください。
-
- 1つのオプションで日本語で以下を言い換える:
平均負荷はCPU利用率の代理ではありません。それらは同じものではありません。
CPU負荷はCPUの需要を意味します。性能の低いCPUはその需要を増やすことがありますが、I/O待ちなど他の要素も同様です。平均負荷は通常、CPUに関連する指標と考えられていますが、CPUだけに関するものではありません。そして、
高い平均負荷は常に追加や高速化されたCPUで軽減できるわけではありません。
これらのメトリックは、サーバーはどのように表現するのでしょうか?
単位の測定
システム上のCPU利用率は、システム全体のCPU容量の割合で表されます。シングルプロセッサシステムでは、総CPU容量は常に100%です。マルチプロセッサシステムでは、容量は正規化または非正規化の二つの異なる方法で表現することができます。
正規化された容量とは、プロセッサーのすべての容量を合わせて100%と考えることを意味します。プロセッサーの数にかかわらず、2つのプロセッサーを備えたシステムの両方のCPUが50%利用されている場合、正規化された総利用率は50%です。
ノーマライズされていない容量は、各プロセッサを100%の容量の単位として数えます。そのため、2つのプロセッサを搭載したシステムは200%の容量を持ち、4つのプロセッサを搭載したシステムは400%の容量を持ちます。もし2つのプロセッサを搭載したシステムの両方のCPUが50%の利用率である場合、ノーマライズされていない総利用率は100%(最大200%の半分)となります。ただし、ノーマライズされていない数値であることを理解していないと、混乱してしまうことがあります。
負荷平均は、再度、すべてのCPUに対して待機中または現在処理中の平均タスク数を表す小数で与えられます。4つのプロセッサを持つシステムでは、4つのプロセッサキューがあり、平均して、4つのCPUがそれぞれ1つのタスクを処理しており、キューに待機中のタスクはありません。その場合、負荷平均は4.0になります。問題ありません。一方、1つのプロセッサシステムで負荷平均が4.0の場合はより心配すべきです。それは平均して、単一のプロセッサが1つのタスクを処理し、キューにはさらに3つのタスクが待機していることを意味します。
ロード平均の値は決して正規化されません。どんなツールでも、4つのプロセッサと4つのタスクがある状態を1.0のロード平均と報告することはありません。平均的に、実行中または待機中の合計タスクが4つある場合、ロード平均は常に4.0になります。CPUの数がいくつであってもです。
つまり、あなたが探索しようとしている指標を理解するために、まずサーバーにいくつのCPUがあるかを知る必要があります。
あなたはCPUをいくつ持っていますか?
すでに2コアのドロップレットをお持ちですが、nprocコマンドに–allオプションを使用すると、サーバー上のプロセッサーの数を表示できます。–allフラグを付けない場合、nprocは現在のプロセスに利用可能な処理ユニットの数を表示しますが、使用中のプロセッサーがある場合は合計プロセッサー数よりも少なくなります。
- nproc –all
2
ほとんどの現代のLinuxディストリビューションでは、lscpuコマンドを使用することもできます。このコマンドでは、プロセッサの数だけでなく、アーキテクチャ、モデル名、速度なども表示されます。
- lscpu
Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 2 On-line CPU(s) list: 0,1 Thread(s) per core: 1 Core(s) per socket: 1 Socket(s): 2 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 63 Model name: Intel(R) Xeon(R) CPU E5-2650L v3 @ 1.80GHz Stepping: 2 CPU MHz: 1797.917 BogoMIPS: 3595.83 Virtualization: VT-x Hypervisor vendor: KVM Virtualization type: full L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 30720K NUMA node0 CPU(s): 0,1 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl eagerfpu pni pclmulqdq vmx ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm vnmi ept fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt arat
CPU利用率と負荷平均の最適な値は何ですか?
サーバーの最適なCPU利用率は役割によって異なります。一部のサーバーはCPUを最大限に活用することを目的としていますが、それ以外のサーバーはそうではありません。統計解析や暗号作業を行うアプリケーションやバッチジョブは、ほぼ常にCPUを最大限に使用しますが、一般的にウェブサーバーはそうではありません。もしウェブサーバーがCPUを完全に使い切っている場合は、ただちにCPUの性能が向上しているサーバーにアップグレードするのではなく、マルウェアや他の問題がCPUサイクルを消費しているかどうかを確認するべきです(合法的であろうとなかろうと)。
サーバーのCPU使用率が100%(正規化)になるのは望ましくありませんが、計算量の多いアプリケーションにおいては、ほぼ100%以下であることが適切です。もしそうでなければ、必要以上のCPUパワーを持っている可能性があり、サーバーのダウングレード(またはサーバーの数を減らす)によってコストを節約することができるかもしれません。
CPU数以下であれば、最適なロード平均値は何であっても問題ありません。2つのプロセッサを持つシステムのロード平均が2.0以下を保持していれば、CPU時間の競合はめったに起こりません。(ただし、キューは時折膨れることがほとんどですが。)
アップタイムで負荷平均値をチェックする。
uptimeコマンドは、負荷平均をすばやく確認するための便利な方法です。システムが他のコマンドラインでの応答が遅い(つまり、負荷が高くなっている)場合でも、軽量で迅速に実行されるため、役に立つことがあります。
アップタイムコマンドは次の内容を表示します:
- the system time
- how long the server has been running
- how many users are currently logged in
- the load average for the past one, five, and fifteen minutes
- uptime
14:08:15 up 22:54, 2 users, load average: 2.00, 1.37, 0.63
この例では、コマンドは午後2時08分に実行され、サーバーはほぼ23時間稼働していました。2人のユーザーがログインしていました。最初の負荷平均値である2.00は、1分間の負荷平均値です。このサーバーは2つのCPUを持っているため、2.00の負荷平均値は、uptimeコマンドが実行される直前の1分間において、平均して2つのプロセスがCPUを使用しており、プロセスが待機していなかったことを意味します。5分間の負荷平均値は、その間、約60%の時間プロセッサがアイドル状態であったことを示します。15分間の値は、さらに利用可能なCPU時間があったことを示しています。これらの3つの数値は、過去15分間でCPUの需要が増加していることを示しています。
このユーティリティは負荷平均の状況を手助け的に示してくれますが、より詳細な情報が必要な場合は、topを参照します。
topを使用してCPU利用率をチェックします。
uptimeと同様に、topもLinuxとUnixの両方のシステムで利用できますが、uptimeと同じ負荷平均値を表示するだけでなく、CPU利用率、メモリ使用量などのシステム全体とプロセス別のデータも提供します。uptimeは実行されて終了するのに対し、topは対話的です。システムリソース使用量のダッシュボードを表示し、常に前面に表示され、数秒ごとに更新され続けます。qを押すことで終了するまで、topは実行を継続します。
top を実行する前に、vServerに作業を割り当ててください。次のコマンドを実行してCPUに負荷をかけてください。
- stress -c 2
別のターミナルをvServerに開き、topを実行してください。
- top
これにより、リソース利用の概要とすべてのシステムプロセスのテーブルが表示されるインタラクティブな画面が表示されます。まずはまず、上部の概要情報をご覧いただきましょう。
ヘッダーブロック
以下はトップの最初の5行です。 (Ika wa toppu no saisho no go-gyō desu.)
top – 22:05:28 up 1:02, 3 users, load average: 2.26, 2.27, 2.19 Tasks: 109 total, 3 running, 106 sleeping, 0 stopped, 0 zombie %Cpu(s): 99.8 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.2 st MiB Mem : 1975.7 total, 1134.7 free, 216.4 used, 624.7 buff/cache MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1612.0 avail Mem
最初の行は、uptimeの出力とほぼ同じです。uptimeと同様に、1分・5分・15分の平均負荷が表示されます。この行とuptimeの出力の唯一の違いは、行の先頭にコマンド名であるtopが表示され、topがデータを更新するたびに時刻が更新されることです。
第2行は、すべてのシステムタスクの状態をまとめています。プロセスの総数がまず表示され、そのうち実行中、スリープ中、停止中、またはゾンビ状態にあるものの数が続きます。
3行目では、CPUの利用状況について説明しています。これらの数値は正規化され、パーセントで表示されます(%記号は含まれません)。したがって、この行のすべての値は、CPUの数に関係なく合計が100%になるはずです。topコマンドを実行する直前に-c(CPU)オプションを指定してstressコマンドを開始したため、最初の数値であるus(ユーザープロセス)は100%近くになるはずです。
第4行目と第5行目は、それぞれメモリとスワップの使用状況について説明しています。このガイドはメモリとスワップの使用状況を探求するものではありませんが、必要な時には参考にしてください。
このヘッダーブロックの後に、各個別のプロセスに関する情報が記載されたテーブルがあります。まもなくそれを見ていきましょう。
以下の例のヘッダーブロックでは、1分間の平均負荷がプロセッサーの数を0.77超えており、わずかな待ち時間のある短いキューを示しています。CPUは100%利用され、十分な空きメモリがあります。
top – 14:36:05 up 23:22, 2 users, load average: 2.77, 2.27, 1.91 Tasks: 117 total, 3 running, 114 sleeping, 0 stopped, 0 zombie %Cpu(s): 98.3 us, 0.2 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.2 si, 1.3 st KiB Mem : 4046532 total, 3244112 free, 72372 used, 730048 buff/cache KiB Swap: 0 total, 0 free, 0 used. 3695452 avail Mem . . .
CPUラインの各項目について詳しく見てみましょう。
- us, user: time running un-niced user processes
This category refers to user processes that were started with no explicit scheduling priority.
Linux systems use the nice command to set a process’s scheduling priority, so “un-niced” means that nice wasn’t used to change the default value. The user and nice values account for all the user processes. High CPU use in this category may indicate a runaway process, and you can use the output in the process table to identify any culprits. - sy, system: time running kernel processes
Most applications have both user and kernel components. When the Linux kernel is doing something like making system calls, checking permissions, or interacting with devices on behalf of an application, the kernel’s use of the CPU is displayed here. When a process is doing its own work, it will appear in either the user figure described above or, if its priority was explicitly set using the nice command, in the nice figure that follows. - ni, nice: time running niced user processes
Like user, nice refers to CPU time that does not involve the kernel. But with nice, the scheduling priority for these tasks was set explicitly. The niceness (priority) of a process is indicated in the fourth column in the process table under the header NI. Processes with a niceness value between 1 and 20 that consume a lot of CPU time are generally not a problem because tasks with normal or higher priority will be able to get processing power when they need it. But if tasks with elevated niceness, between -1 and -20, are taking a disproportionate amount of CPU time, they can easily affect the responsiveness of the system and warrant further investigation. Note that many processes that run with the highest scheduling priority, -19 or -20 depending on the system, are spawned by the kernel to do important tasks that affect system stability. If you’re not sure about the processes you see, it’s prudent to investigate them rather than killing them. - id, idle: time spent in the kernel idle handler
This figure indicates the percentage of time that the CPU was both available and idle. A system is generally in good working order with respect to CPU when the user, nice, and idle figures combined are near 100%. - wa, IO-wait: time waiting for I/O completion
The IO-wait figure shows how much time a processor has spent waiting for I/O operations to complete. Read/write operations for network resources like NFS and LDAP will count in IO-wait as well. As with idle time, spikes here are normal, but any kind of frequent or sustained time in this state suggests an inefficient task, a slow device or network, or a potential hard disk problem. - hi, hardware interrupts: time spent servicing hardware interrupts
This is the time spent on physical interrupts sent to the CPU from peripheral devices like disks and hardware network interfaces. When the hardware interrupt value is high, you may have a peripheral device that has gone bad. - si, software interrupts: time spent servicing software interrupts
Software interrupts are sent by processes rather than physical devices. Unlike hardware interrupts that occur at the CPU level, software interrupts occur at the kernel level. When the software interrupt value is high, investigate the specific processes that are using the CPU. - st, steal: time stolen from this vm by the hypervisor
The steal value shows how long a virtual CPU spends waiting for a physical CPU while the hypervisor is servicing itself or a different virtual CPU. Essentially, the amount of CPU use in this field indicates how much processing power your VM is ready to use, but which is not available to your application because it is being used by the physical host or another virtual machine. Generally, seeing a steal value of up to 10% for brief periods of time is not a cause for concern. Larger amounts of steal for longer periods of time may indicate that the physical server has more demand for CPU than it can support.
頭部のtopのCPU使用状況の要約を見たので、それに続いて、下に表示されるプロセステーブルを見て、CPUに関連する列に注意を払います。
プロセステーブル
例えば、トップの出力のプロセステーブルの最初の6行をこちらに示します。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 9966 sammy 20 0 9528 96 0 R 99.7 0.0 0:40.53 stress 9967 sammy 20 0 9528 96 0 R 99.3 0.0 0:40.38 stress 7 root 20 0 0 0 0 S 0.3 0.0 0:01.86 rcu_sched 1431 root 10 -10 7772 4556 2448 S 0.3 0.1 0:22.45 iscsid 9968 root 20 0 42556 3604 3012 R 0.3 0.1 0:00.08 top 9977 root 20 0 96080 6556 5668 S 0.3 0.2 0:00.01 sshd . . .
以下のヘッダーの下に、サーバー上にある全てのプロセスが、どの状態であるかに関わらずリストされています。デフォルトでは、プロセステーブルは%CPUの列でソートされているため、CPU時間を最も消費しているプロセスが一番上に表示されます。
%CPUの値はパーセントで表示されますが、ヘッダーのCPU使用率とは異なり、プロセステーブルの値は正規化されていません。したがって、この2コアシステムでは、プロセステーブルのすべての値の合計は、両方のプロセッサが完全に使用されている場合には200%になるはずです。
Note
注意:正規化された値を表示したい場合は、IrixモードからSolarisモードに切り替えるために、SHIFT+Iを押してください。%CPUの値の合計が100%を超えなくなります。Solarisモードに切り替えると、Irixモードがオフになったという簡単なメッセージが表示され、この例では、ストレスプロセスの値がそれぞれほぼ100%から約50%に切り替わります。
出力 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10081 サミー 20 0 9528 96 0 R 50.0 0.0 0:49.18 ストレス
10082 サミー 20 0 9528 96 0 R 50.0 0.0 0:49.08 ストレス
1439 ルート 20 0 223832 27012 14048 S 0.2 0.7 0:11.07 snapd
1 ルート 20 0 39832 5868 4020 S 0.0 0.1 0:07.31 システムディ
異なるキーストロークを使用して、topおよびサーバーのプロセスをインタラクティブに制御することができます。
- SHIFT-M to sort processes by memory usage.
- SHIFT-P to sort processes by CPU usage.
- k, followed by a process ID (PID) and a signal, to kill an unruly process. After entering a PID, try a signal of 15 (SIGTERM) first, which is the default. Do not use 9 (SIGKILL) carelessly.
- r, followed by a process ID, to renice (reprioritize) a process.
- c to toggle the command descriptions between a short description (the default) and the full command string.
- d to change the refresh interval for the figures in top.
他の多くの機能もあります。詳細については、topのマニュアルページ(man top)をお読みください。
これまでに、負荷平均とCPU利用率を調べるためによく使われる2つのLinuxコマンドを確認しました。これらのツールは便利ですが、サーバーの状態を一時的なウィンドウでしか確認できません。topを見続けることはできる時間には限りがあります。サーバーリソースの長期的な使用パターンをより良く把握するには、モニタリングソリューションが必要です。次のセクションでは、Silicon Cloud vServersで追加費用なしで利用できるモニタリングツールについて簡単に調査します。
デジタルオーシャンのモニタリングによる時間経過に対するメトリクスの追跡
デフォルトでは、コントロールパネルでvServerの名前をクリックすると、すべてのvServerには帯域幅、CPU、およびディスクI/Oのグラフが表示されます。これらの3つのグラフを取得するためには、Silicon Cloudエージェントをインストールする必要はありません。
これらのグラフは、過去1時間、6時間、24時間、7日間、および14日間の各リソースの使用状況を視覚的に表します。CPUグラフは、CPUの利用状況に関する情報を提供します。濃い青の線はユーザープロセスによるCPUの使用を示しています。薄い青はシステムプロセスによるCPUの使用を示しています。グラフ上の値とその詳細は、仮想コアの数に関係なく、全体の容量が100%になるように正規化されています。
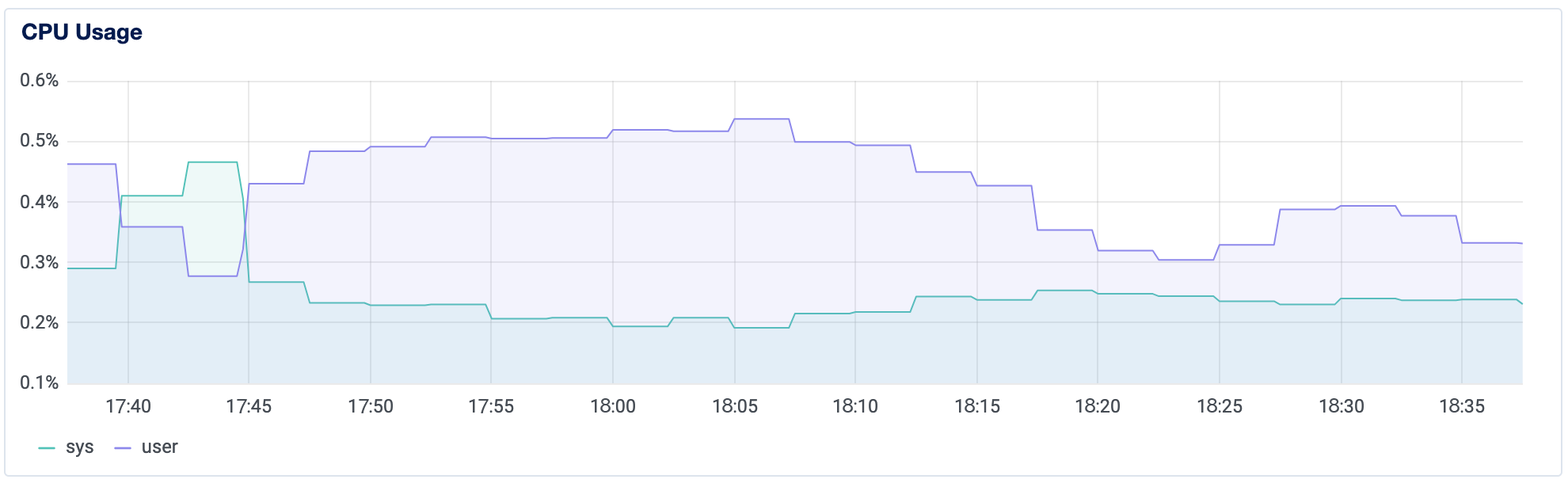
グラフを見ると、使用量が断続的なのか持続的なのかがわかります。これは、サーバーのCPU使用率のパターンの変化を見つけるのに役立ちます。
デフォルトのグラフに加えて、Silicon CloudエージェントをvServerにインストールして、平均負荷、ディスク使用量、およびメモリ使用量などの追加データを収集および表示することができます。エージェントを使用すると、システムのアラートポリシーを設定することもできます。「Silicon Cloud監視のためのエージェントのインストールと使用方法」は、設定方法についての役立つ情報です。
エージェントをインストールしたら、リソースの使用状況について通知するアラートポリシーを設定できます。選ぶしきい値は、サーバーの典型的なワークロードによって異なります。
Note
注意事項:Silicon Cloudのモニタリングエージェントをインストールする際には次のようなことがあります:
CPU利用率に関しては、1つの値しか表示されません。システムとユーザースペースの利用率が表示されなくなります。
エージェントをインストールする前の全てのメトリクスの履歴は失われます。
例えば、アラート
変化の監視:CPU使用率が1%を超えている
もしvServerを主にコードの統合や浸透テストに使用している場合、サーバーにプッシュされた新しいコードがCPU使用率を増加させているかどうかを検出するため、歴史的なパターンよりわずかに高いアラートを設定することができます。CPUが1%に達しない上記のグラフの場合、5分間の1% CPU使用率の閾値は、コードによる変更がCPU使用に影響を与える可能性があることを早期に警告することができます。
デジタルオーシャンのコントロールパネルで、左側の「管理」メニューの下にある「モニタリング」をクリックしてください。デフォルトでハイライトされた「リソースアラート」タブの下にある、「リソースアラートの作成」をクリックしてください。フォームに入力し、「リソースアラートの作成」ボタンをクリックしてください。
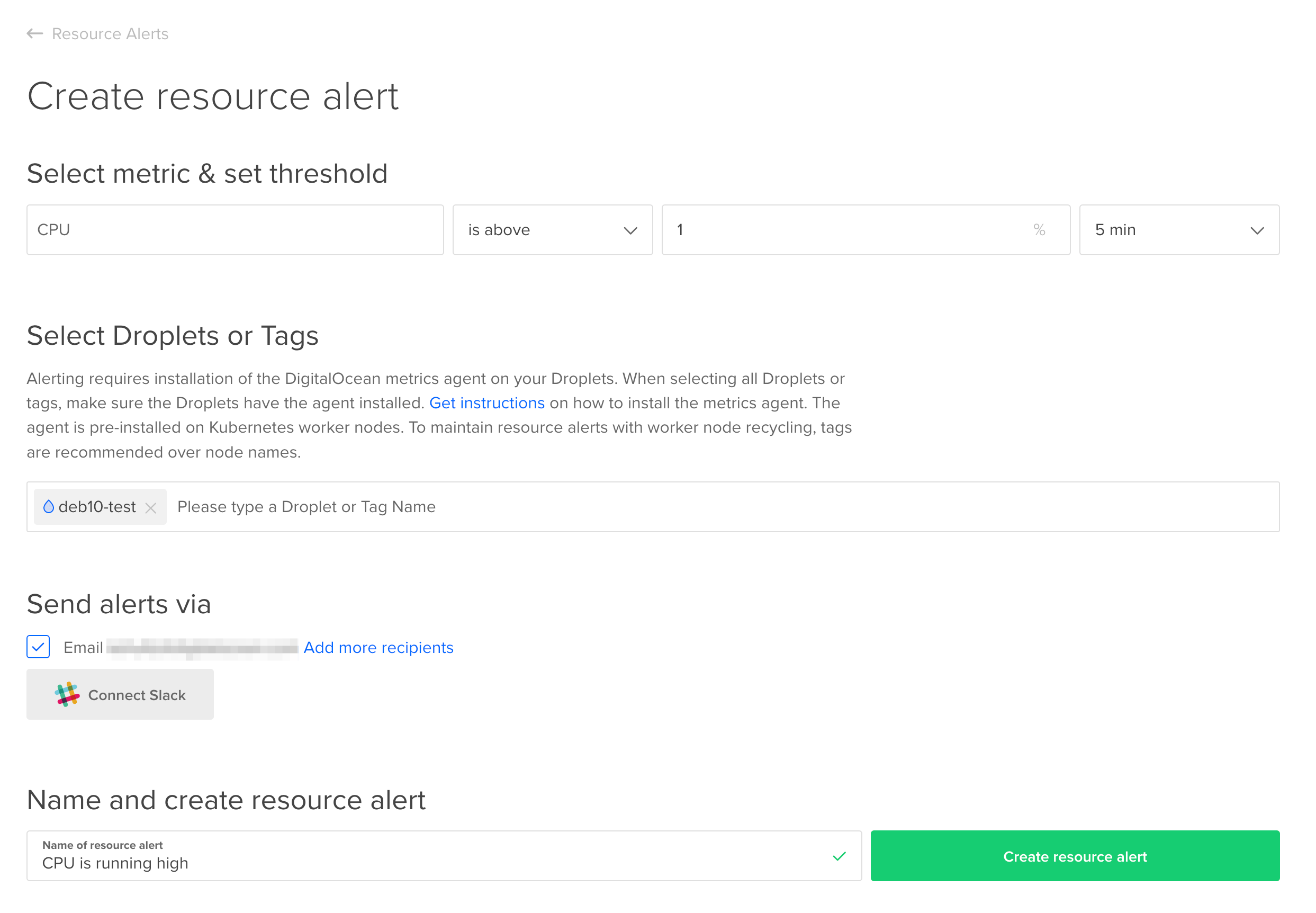
ほとんどのシステムでは、この閾値は完全に適切ではない可能性が高いですが、過去数週間のCPUグラフを調べることで通常のワークロード中の典型的なCPU利用率を特定できれば、通常の利用率よりわずかに高い閾値でアラートを作成し、新しいコードや新しいサービスがCPU利用率に影響を与えた際の早期知識を得ることができます。
緊急事態の監視:CPU利用率が90%を超えた場合
平均値よりもはるかに高い閾値を設定することも考慮してください。重要とみなし、即座の調査を必要とすると判断する閾値です。例えば、定期的に50%のCPU使用率を持っているサーバーが突然90%に急上昇した場合、すぐにログインして状況を調査することが望ましいでしょう。また、閾値はシステムの作業負荷に特化しています。
結論
この記事では、CPU利用率と負荷平均を提供するLinuxの2つの一般的なユーティリティであるuptimeとtopについて探求しました。また、Silicon Cloud Monitoringを使用してvServerの過去のCPU利用率を確認し、変更や緊急事態に対応する方法も説明しました。Silicon Cloud Monitoringについて詳しくは、「メトリクス、モニタリング、アラートの紹介」を読んでください。また、ドキュメントも参照してください。
ワークロードに必要なvServerの種類を決めるためには、「適切なvServerプランを選ぶ」というガイドを読んでください。

