R语言计算标准差的完整指南:从基础到高级应用
作为一种统计语言,R 提供了标准函数 sd() 来计算数值的标准差。
那么标准差是什么呢?
- 标准差是衡量数值离散程度的度量。
- 标准差越高,数值的分布范围越广。
- 标准差越低,数值的分布范围越窄。
- 简单来说,公式定义为 – 标准差是’方差’的平方根。
标准差的重要性
标准差在统计学中非常受欢迎,但为什么呢?它的受欢迎程度和重要性的原因列举如下。
- 标准差通过平方运算将负数转换为正数。
- 它显示了较大的偏差,使您可以特别关注它们。
- 它显示了集中趋势,这是分析中非常有用的功能。
- 它在金融、商业、分析和测量中扮演着重要角色。
在我们进入主题之前,请牢记这个定义!
方差 – 定义为观测值与期望值之间的平方差异。
在R中找到列表中的标准差
用这种方法,我们将创建一个名为’x’的列表,并向其添加一些值。然后我们可以计算列表中这些值的标准偏差。
x <- c(34,56,87,65,34,56,89) #创建包含一些值的列表'x'
sd(x) #计算列表'x'中值的标准差
输出结果为 22.28175。
现在我们可以尝试从列表’y’中提取特定值来找到标准偏差。
y <- c(34,65,78,96,56,78,54,57,89) #创建包含一些值的列表'y'
data1 <- y[1:5] #使用索引提取特定值
sd(data1) #计算列表中索引或提取的值的标准差
输出 —> 23.28519
计算存储在CSV文件中的数值的标准偏差
在这种方法中,我们正在导入一个CSV文件,以在该文件中存储的值上使用R语言计算标准差。
readfile <- read.csv('testdata1.csv') #读取CSV文件
data2 <- readfile$Values #获取存储在'Values'标题下的值
sd(data2) #计算标准差
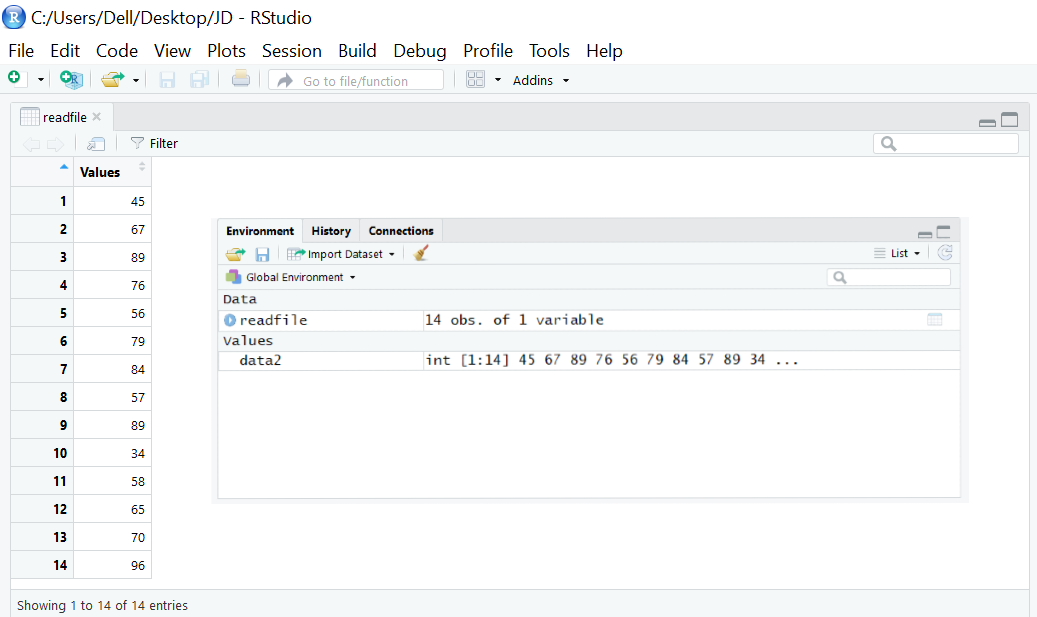
输出结果为17.88624。
高低标准差
通常情况下,在标准差较低的情况下,数值将非常接近平均值;而在标准差较高的情况下,数值将远离平均值。
我们可以用一个例子来说明这个问题。
x <- c(79,82,84,96,98) # 创建数据向量
mean(x) # 计算平均值
--> 82.22222
sd(x) # 计算标准差
--> 10.58038
使用R语言编写以下代码以在条形图中绘制这些数据值。
要安装ggplot2包,在R Studio中运行以下代码。
# 安装ggplot2包
install.packages(“ggplot2”)
library(ggplot2) # 加载ggplot2包
values <- data.frame(marks=c(79,82,84,96,98), students=c(0,1,2,3,4,)) # 创建数据框
head(values) # 显示数据框的值
marks students
1 79 0
2 82 1
3 84 2
4 96 3
5 98 4
x <- ggplot(values, aes(x=marks, y=students))+geom_bar(stat='identity') # 创建条形图
x # 显示图形

在上述结果中,您可以观察到大部分数据都聚集在均值(79、82、84)附近,这表明它是一个低标准差。
下面展示一个高标准差的例子:
y <- c(23,27,30,35,55,76,79,82,84,94,96)
mean(y)
---> 61.90909
sd(y)
---> 28.45507
要使用R中的ggplot绘制柱状图来表示这些值,请运行以下代码。
library(ggplot2)
values <- data.frame(marks=c(23,27,30,35,55,76,79,82,84,94,96), students=c(0,1,2,3,4,5,6,7,8,9,10))
head(values) #显示这些值
marks students
1 23 0
2 27 1
3 30 2
4 35 3
5 55 4
6 76 5
x <- ggplot(values, aes(x=marks, y=students))+geom_bar(stat='identity')
x #显示图表
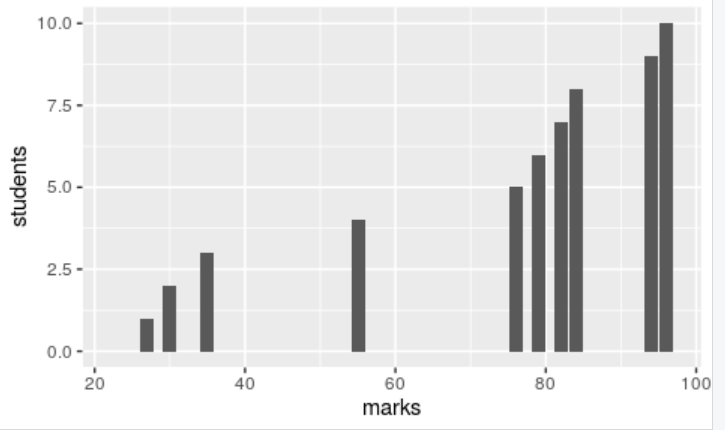
在上述结果中,您可以看到数据分布范围较大。最低分为23分,与平均分61分相差甚远,这表明数据具有高标准偏差。
到目前为止,您已经对在R语言中使用sd()函数计算标准差有了相当的理解。让我们通过解决几个简单的问题来总结本教程。
示例1:计算1-20之间(不包括1和20)的偶数的标准差
解决方案:1到20之间的偶数为:
2、4、6、8、10、12、14、16、18
现在我们来计算这些数值的标准差。
x <- c(2,4,6,8,10,12,14,16,18) #1到20之间的偶数列表
sd(x) #计算1到20之间偶数列表中这些值的标准差
输出结果:5.477226
示例2:计算美国人口数据的标准差
计算美国各州人口的标准差。为此,我们需要导入CSV文件并读取数值,计算标准差,并在R中绘制结果的直方图。
df<-read.csv("population.csv") #读取CSV文件
data<-df$X2018.Population #从人口列中提取数据
mean(data) #计算平均值
View(df) #显示数据
sd(data) #计算标准差
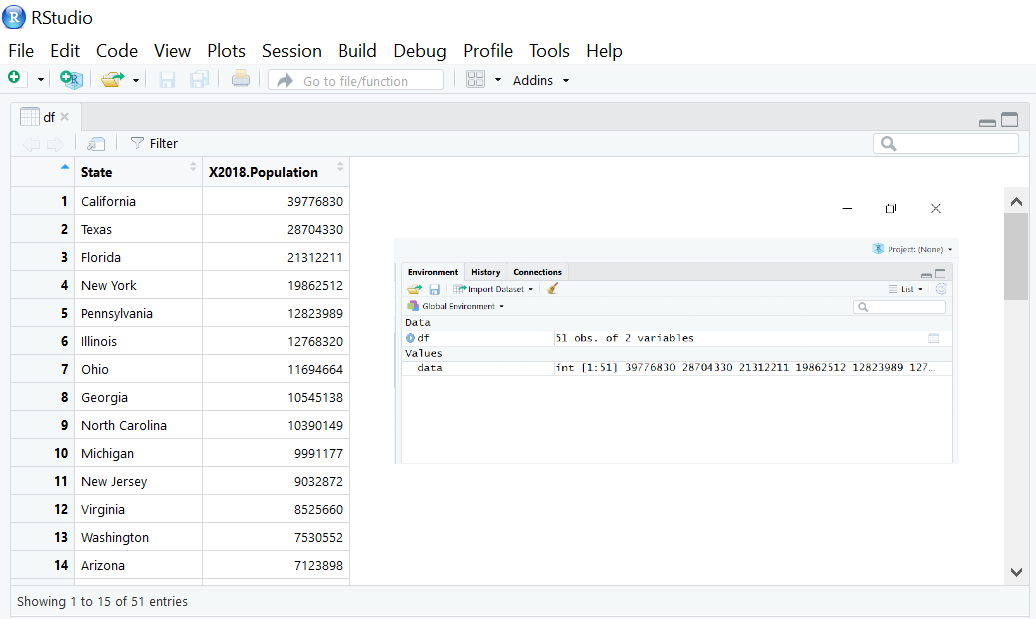
输出结果:平均值 = 6432008,标准差 = 7376752
结论
在R中计算数值的标准差非常简单。R提供了标准函数sd()来计算标准差。您可以创建一个数值列表或导入CSV文件来计算标准差。
重要提示:不要忘记根据以上所示的索引从文件或列表中提取相应的数值来计算标准差。
如果您对R中的sd()函数有任何疑问,请在评论框中留言。祝学习愉快!

