R语言绘制ROC曲线完全指南:从入门到精通
大家好!在这篇文章中,我们将会详细了解机器学习的一个重要错误指标——在R编程中绘制ROC曲线。
好的,让我们开始吧!
ROC曲线的必要性错误指标使我们能够评估和验证模型在特定数据集上的运行情况。
ROC图是其中一种错误指标。
ROC曲线,也被称为ROC AUC曲线,是一种分类错误指标。换句话说,它衡量了分类机器学习算法的功能和结果。
准确来说,ROC曲线代表数值的概率曲线,而AUC则是不同数值/标签组之间可分性的度量。通过ROC AUC曲线,我们可以分析并得出结论,模型根据标签正确地将多少数值进行了区分和分类。
AUC值越高,预测值的分类效果就越好。
以一个模型来预测和分类抛硬币的结果是“正面”还是“反面”。
所以,如果AUC分数高,表示该模型能够更有效地将“正面”分类为“正面”和“反面”分类为“反面”。
从技术角度来看,ROC曲线是根据模型的真正例率和假正例率绘制的。
让我们现在试着在接下来的部分中实现ROC曲线的概念吧!
方法一:使用plot()函数。我们可以使用ROC曲线来评估机器学习模型,就像之前讨论过的一样。因此,让我们尝试在逻辑回归模型中实现ROC曲线的概念。
让我们开始吧!:)
在这个例子中,我们将使用银行贷款违约数据集进行逻辑回归建模。我们将使用来自“pROC”库的plot()函数绘制ROC曲线。你可以在这里找到数据集!
-
- 最初,我们使用read.csv()函数将数据集加载到环境中。
-
- 在建模之前,数据集的拆分是一个关键步骤。因此,我们使用R文档中的createDataPartition()函数将数据集分为训练数据和测试数据。
-
- 我们设置了一些错误指标来评估模型的运行情况,包括精确度、召回率、准确度、F1分数、ROC曲线等。
-
- 最后,我们使用R的glm()函数在数据集上应用逻辑回归。然后,我们使用predict()函数在测试数据上测试模型并获得错误指标的值。
- 最后,我们通过roc()方法计算模型的roc AUC分数,并使用’pROC’库中可用的plot()函数绘制相应的图形。
rm(list = ls())
#Setting the working directory
setwd("D:/Edwisor_Project - Loan_Defaulter/")
getwd()
#Load the dataset
dta = read.csv("bank-loan.csv",header=TRUE)
### Data SAMPLING ####
library(caret)
set.seed(101)
split = createDataPartition(data$default, p = 0.80, list = FALSE)
train_data = data[split,]
test_data = data[-split,]
#error metrics -- Confusion Matrix
err_metric=function(CM)
{
TN =CM[1,1]
TP =CM[2,2]
FP =CM[1,2]
FN =CM[2,1]
precision =(TP)/(TP+FP)
recall_score =(FP)/(FP+TN)
f1_score=2*((precision*recall_score)/(precision+recall_score))
accuracy_model =(TP+TN)/(TP+TN+FP+FN)
False_positive_rate =(FP)/(FP+TN)
False_negative_rate =(FN)/(FN+TP)
print(paste("Precision value of the model: ",round(precision,2)))
print(paste("Accuracy of the model: ",round(accuracy_model,2)))
print(paste("Recall value of the model: ",round(recall_score,2)))
print(paste("False Positive rate of the model: ",round(False_positive_rate,2)))
print(paste("False Negative rate of the model: ",round(False_negative_rate,2)))
print(paste("f1 score of the model: ",round(f1_score,2)))
}
# 1. Logistic regression
logit_m =glm(formula = default~. ,data =train_data ,family='binomial')
summary(logit_m)
logit_P = predict(logit_m , newdata = test_data[-13] ,type = 'response' )
logit_P <- ifelse(logit_P > 0.5,1,0) # Probability check
CM= table(test_data[,13] , logit_P)
print(CM)
err_metric(CM)
#ROC-curve using pROC library
library(pROC)
roc_score=roc(test_data[,13], logit_P) #AUC score
plot(roc_score ,main ="ROC curve -- Logistic Regression ")
输出: 只需要一种选择,将以下内容用中国母语进行释义。
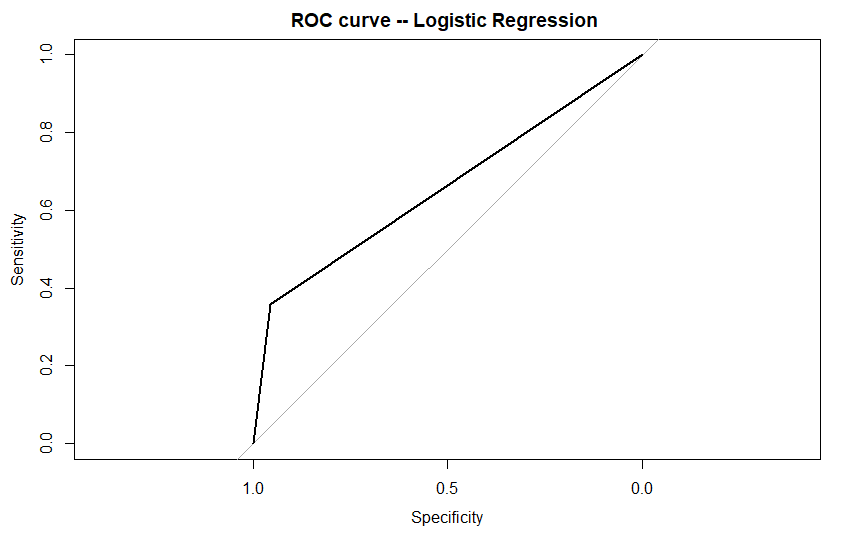
第二种方法:使用roc.plot()函数
R编程为我们提供了另一个名为”verification”的库,用于绘制模型的ROC-AUC曲线。
为了使用这个功能,我们需要将”验证”库安装和导入到我们的环境中。
完成这个步骤后,我们使用roc.plot()函数绘制数据,以清晰评估数据值之间的”敏感性”和”特异性”如下所示。
# 安装verification包
install.packages("verification")
# 加载verification库
library(verification)
# 创建数据
x <- c(0, 0, 0, 1, 1, 1)
y <- c(.7, .7, 0, 1, 5, .6)
data <- data.frame(x, y)
# 为数据列命名
names(data) <- c("yes", "no")
# 绘制ROC曲线
roc.plot(data$yes, data$no)
输出结果:

结论
通过这个话题,我们已经到达了终点。如果你有任何问题,请随时在下方评论。
尝试将ROC曲线概念应用到其他机器学习模型中,并在评论区告诉我们你对此的理解。
一直保持关注,快乐学习! 🙂

