服务器端PDF与图像OCR:高效文本识别指南
简介
光学字符识别(OCR)主要用于将扫描图像中的文字转换为可选择、可复制、可编码和可嵌入的文本。许多现代桌面和移动应用程序以及扫描软件都内置了OCR功能,并且大多数流通的PDF文档都嵌入了文本。然而,您仍可能遇到包含大量非嵌入文本的文件或图像,无法自动提取。
在这种情况下,您可以使用一套开源工具的流程来自动执行光学字符识别。如果您正在将文档或图像导入到需要提取文本的网络应用程序中,或者您正在处理一大批需要对其全文建立索引的文档,这将非常有用。
本教程将介绍如何使用Ghostscript、Tesseract和PDFtk设置OCR流程。您还将了解其他可以替代或用于此基线功能的工具。
先决条件
大多数平台都提供这些工具。本教程将为Ubuntu 22.04服务器提供安装说明,请按照我们的Ubuntu 22.04初始服务器设置指南进行操作。
步骤1 – 安装Ghostscript、Tesseract和PDFtk
OCR可以在包含图像内容的PDF和独立图片上执行。处理PDF时需要一些额外的步骤,如果您只处理图片本身,可以跳过这些步骤。
您将需要三个工具来进行整体流程处理:Ghostscript,它处理各种PDF和图像之间的转换(最初是作为Postscript的解释器而创建的,Postscript是PDF的前身技术);Tesseract,一个开源OCR引擎,与Ghostscript一样,自1980年代以来一直在不断发展;以及PDFtk,一个用于从单个页面切片或重建PDF的较小实用工具。
这三个应用程序都可以在Ubuntu的默认仓库中找到,并且可以通过apt包管理器进行安装。使用apt update更新软件源,然后使用apt install来安装它们。
- sudo apt update
- sudo apt install pdftk ghostscript tesseract-ocr x11-utils
您现在应该有三个新的命令存在,每个命令对应一个应用程序,您可以通过使用which命令进行验证。
- which pdftk
/usr/bin/pdftk
- which gs
/usr/bin/gs
- which tesseract
/usr/bin/tesseract
在下一步中,您将使用这些命令来执行OCR操作。
第二步 – 将PDF转换为图像并运行Tesseract
如果您还没有需要进行OCR的PDF文件,您可以通过下载这个样本PDF文件来跟随本教程,该文件是没有任何嵌入文本的扫描文件。要将PDF文件下载到您的服务器上,您可以使用带有-O标记的curl命令,将其保存在当前目录下并使用相同的文件名。
- curl -O https://deved-images.nyc3.cdn.digitaloceanspaces.com/server-ocr/OCR-sample-paper.pdf
如果您正在使用一个或多个PDF文件,您需要将它们转换为单独的图像,才能用作OCR的源文件。这可以使用Ghostscript命令来完成。您需要添加额外的参数来保持DPI、颜色空间和尺寸的一致性。首先,为此过程创建一个工作输出目录,然后运行gs命令。
- mkdir output
- gs -o output/%05d.png -sDEVICE=png16m -r300 -dPDFFitPage=true OCR-sample-paper.pdf
这个gs命令在其他命令之前使用了-o标志来指定输出路径。%05d是Ghostscript能够本地理解的晦涩的Shell语法,这种情况下它表示使用自动递增的5位数字为输入的PDF文件命名输出的PNG文件。您可能在其他旧的命令行应用程序中看到这种使用方法。在添加一些PNG格式化语法和一个DPI值为-r300之后,提供OCR-sample-paper.pdf或您选择的输入文件的路径。
Ghostscript会将PDF中的每一页单独输出。
Processing pages 1 through 14. Page 1 Page 2 Page 3 Page 4 Page 5 …
在完成后,您可以验证输出目录的内容。
- ls output
这是文章《如何对PDF和图像执行服务器端OCR》的第2部分(共4部分)。
接下来,你将使用一个shell循环来围绕一个Tesseract命令,将你创建的图像转换回单独的PDF页面,这次包含嵌入式文本。Shell循环与其他编程语言中的循环行为类似,你可以通过使用分号将每个部分分隔开来将它们格式化为一个单一的命令,最后以done结束。
for png in $(ls output); do tesseract -l eng output/$png output/$(echo $png | sed -e "s/\.png//g") pdf; done在命令循环期间,一些文本将被输出到你的终端。
Tesseract Open Source OCR Engine v4.1.1 with Leptonica
Tesseract Open Source OCR Engine v4.1.1 with Leptonica
Tesseract Open Source OCR Engine v4.1.1 with Leptonica
Tesseract Open Source OCR Engine v4.1.1 with Leptonica
...Tesseract语法本身就是这个组件:tesseract -l 语言 输入文件名 输出基础文件名 [pdf]。如果省略-l 语言组件,Tesseract默认使用英语语言模型;如果省略pdf,Tesseract将把识别出的文本作为与输入图像分开的文件输出,而不是以PDF格式输出。此命令中添加的额外sed语法确保向Tesseract提供正确的路径,并在将输出文件名更改为.pdf时删除.png文件扩展名。
注意:在Ubuntu上,默认情况下Tesseract不会安装所有语言模型。如果您需要进行非英语光学字符识别,请使用sudo apt install tesseract-ocr-all安装tesseract-ocr-all软件包。您可以在官方文档中找到更多关于Tesseract命令行用法的示例。
在运行Tesseract后再次检查输出目录。
ls output你将看到你新创建的所有PDF页面。
00001.pdf 00003.pdf 00005.pdf 00007.pdf 00009.pdf 00011.pdf 00013.pdf
00001.png 00003.png 00005.png 00007.png 00009.png 00011.png 00013.png
00002.pdf 00004.pdf 00006.pdf 00008.pdf 00010.pdf 00012.pdf 00014.pdf
00002.png 00004.png 00006.png 00008.png 00010.png 00012.png 00014.png如果你只需要一个输出图像,可以直接跳到本教程的最后步骤,详细了解批量文本提取选项。如果你正在使用PDF文件,你将在下一步进行重建和最终处理。
第三步(可选)-从图像输出进行PDF重建
这是文章《如何对PDF和图像执行服务器端OCR》的第3部分(共4部分)。
内容片段:如果你在上一步使用了PDF作为输入,现在你需要再次使用PDFtk和Ghostscript来将Tesseract生成的单个页面重新组合起来。因为它们是按顺序编号的,你可以使用shell语法将文件的有序列表传递给pdftk cat命令,进行拼接:
pdftk output/*.pdf cat output joined.pdf您现在有一个由Tesseract输出重新构建的PDF文档,名为joined.pdf。唯一剩下的步骤是使用Ghostscript重新格式化该PDF文档。这一步骤很重要,因为Tesseract并不总是准确地保持PDF的尺寸。您的新PDF文档当前比输入文件要大得多,因为它还未经过优化,而Ghostscript则是一个更强大的工具,可以精确重新呈现PDF的规格。在joined.pdf上执行最后一个gs命令即可。
gs -sDEVICE=pdfwrite -sPAPERSIZE=letter -dFIXEDMEDIA -dPDFFitPage -o final.pdf joined.pdf您可能会从这个命令中收到一些关于PDF规范符合性的警告输出,这是正常的。Ghostscript对于PDF标准的要求比其他工具更严格,大多数PDF文件可以在大多数查看器中正确显示。
以下参数-sDEVICE=pdfwrite、-sPAPERSIZE=letter、-dFIXEDMEDIA、-dPDFFitPage均用于强制PDF尺寸。如果使用不同的页面格式,您可能需要更改sPAPERSIZE=letter。提供给gs命令的-o final.pdf文件名将是您最终输出的名称。
为了测试OCR是否成功,您可以在桌面应用程序中本地打开PDF,或者您可以使用类似pdftotext的命令行应用程序将文档中现在嵌入的文本提取出来。
你可以通过一个叫做poppler-utils的软件包在Ubuntu上安装pdftotext,该软件包包含多个命令行工具,用于处理PDF文档。
sudo apt install poppler-utils接下来,在你的新PDF上运行pdftotext。
pdftotext final.pdf将创建一个新文件final.txt。可以使用像head这样的工具预览该文件的内容。
head final.txtPakistan Journal of Applied Economics (1983) vol. II, no. 2 (167—180) THE MEASUREMENT OF FARM-SPECIFIC TECHNICAL EFFICIENCY K. P. KALIRAJAN and J. C, FLINN* Measures of technical efficiency were estimated using a stochastic translog production frontier for a sample of rainfed rice farmers in Bicol, Philippines. These estimates were farm specific as opposed to being based on deviations from an average sample efficiency. A wide variation in the level of technical你应该从输入文件中获取一串文本。它可能是无序的或包含一些奇怪的格式字符,但当一次性倾倒出所有文本时是正常的——重要的是,该文档现在包含了嵌入的文本。此时,你可以删除包含工作进展图像和PDF页面的输出目录。这些图像不再需要了。
现在,您可以使用三个工具和四个命令来构建一个完整的PDF OCR流程。这些工具可以组合成一个独立的脚本,集成到其他应用程序中,或按需进行交互式运行。这是处理单个PDF文档的完整解决方案。接下来,您将了解一些格式化数据表和批量文本提取的其他选项。
第四步(可选)- 从OCR文档中提取CSV表格
在对图像或PDF进行OCR之后,您还可以选择将任何表格或电子表格格式的数据提取到CSV文件中。当处理旧数据源或科学论文时,这可能特别有用。
有两种工具可以提供这个功能,它们的表现都相似:Java编写的Tabula和Python编写的Camelot。
Tabula
在Ubuntu上,您可以使用snap安装工具将Tabula作为一个snap软件包进行安装。
sudo snap install tabula如果你在这个教程中检查样本PDF的视觉效果,你会发现在第6页中间有一张表格。
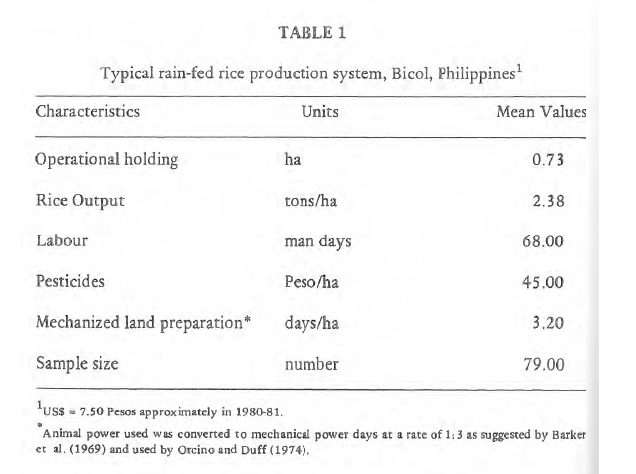
因此,您将通过在final.pdf中指定要提取的表格在-p 6上运行tabula,并将输出重定向到一个名为test.csv的新文件。
tabula -p 6 final.pdf > test.csv检查test.csv中对表格检测的质量。现在你可以将其作为输入,用于类似Excel这样的电子表格程序,或另一个数据分析脚本。
Camelot
这是文章《如何对PDF和图像执行服务器端OCR》的第4部分(共4部分)。
Camelot是一个Python库,需要您已经安装了Python和pip(Python包管理器)。如果您还没有安装Python,可以参考《如何在Ubuntu 22.04服务器上安装Python 3并设置编程环境》的第一步。
接下来,使用pip install命令安装Camelot,同时安装其opencv依赖库:
sudo pip install camelot-py opencv-python-headless ghostscript在此之后,您可以再次运行Camelot处理PDF,指定页码-p 6,输出路径和文件类型,以及输入文件final.pdf:
camelot -p 6 -f csv -o test.csv stream final.pdf如果需要,您可以参考Camelot文档对提取结果进行微调。
在本教程的最后一个可选步骤中,您将回顾一些其他OCR解决方案。
第五步(可选)- 使用其他OCR解决方案进行批量提取
尽管Tesseract是发展最久的开源OCR工具,支持最广泛的输出格式,但还有一些其他选项可用于执行服务器端OCR。EasyOCR是一个较新的开源OCR引擎,正在积极开发中,并且通过在GPU上运行可以提供更快或更准确的结果。然而,EasyOCR不支持PDF输出,这使得重构输入文档变得困难,并且主要用于输出大量的原始文本。
EasyOCR是一个Python库,需要您已经安装了Python和pip(Python的包管理器)。如果您尚未安装Python,可以参考《如何在Ubuntu 22.04服务器上安装Python 3并设置编程环境》中的第一步。
接下来,使用pip install命令安装EasyOCR:
sudo pip install easyocr在安装EasyOCR之后,您可以将其作为Python脚本中的库使用,或者可以直接通过使用easyocr命令在命令行中调用它。一个示例的EasyOCR命令如下:
easyocr -l ch_sim en -f image.jpg --detail=1 --gpu=TrueEasyOCR支持同时加载多个语言模型以进行多语言OCR。您可以使用-l标志指定多种语言,例如用ch_sim表示简体中文,en表示英文。-f image.jpg是您输入文件的路径。如果您需要参考文件中提取文本的位置,--detail=1将提供边界框坐标与输出一起。您也可以使用--detail=0省略此信息。
如果已经配置了GPU环境,可以选择性地使用--gpu=True标志,并尝试使用CUDA代码路径进行更高效的提取。
结论
在本教程中,您使用了几个成熟的开源工具创建了一个OCR流程,可以将其应用于其他应用程序堆栈中或通过网络服务公开。您还回顾了一些用于微调的工具语法和选项,并考虑了一些其他OCR选项,用于提取CSV表格以及运行大规模的文本批量提取。
OCR(光学字符识别)是一项被广泛理解和使用的技术:您知道何时需要它。尽管如此,现成的OCR实现通常仅限于付费的桌面软件。能够在需要的任何地方部署OCR工具可能非常有用。接下来,您可能想阅读《机器学习简介》以复习一些相关的主题领域。

