Spring Batch批处理框架实战教程与示例
这是文章《Spring Batch示例》的第1部分(共6部分)。
欢迎来到Spring Batch示例。Spring Batch是一个用于执行批处理作业的Spring框架模块。我们可以使用Spring Batch来处理一系列作业。
Spring Batch示例
在进行Spring Batch示例程序之前,让我们对Spring Batch的术语有一些了解。
- 一个作业可以由’n’个步骤组成。每个步骤包含读取-处理-写入任务,或者它可以有一个单一操作,称为tasklet(任务片)。
- 读取-处理-写入基本上是从数据库、CSV等源读取数据,然后处理数据并将其写入数据库、CSV、XML等源。
- Tasklet(任务片)意味着执行单一任务或操作,如在处理完成后清理连接、释放资源。
- 读取-处理-写入和tasklets(任务片)可以链接在一起以运行作业。
Spring Batch示例
让我们考虑一个关于Spring Batch实现的工作示例。我们将考虑以下的实现场景:一个包含数据的CSV文件需要转换为XML,并且数据和标签将根据列名命名。以下是用于Spring Batch示例的重要工具和库。
- Apache Maven 3.5.0 – 用于项目构建和依赖管理。
- Eclipse Oxygen Release 4.7.0 – 用于创建Spring Batch Maven应用的IDE。
- Java 1.8
- Spring Core 4.3.12.RELEASE
- Spring OXM 4.3.12.RELEASE
- Spring JDBC 4.3.12.RELEASE
- Spring Batch 3.0.8.RELEASE
- MySQL Java Driver 5.1.25 – 根据你的MySQL安装使用。这是Spring Batch元数据表所需的。
Spring Batch示例目录结构

Spring Batch的Maven依赖
这是文章《Spring批处理示例》的第2部分(共6部分)。
下面是pom.xml文件的内容,包含了我们的Spring批处理示例项目所需的所有依赖项。
<project xmlns="https://maven.apache.org/POM/4.0.0" xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.Olivia.spring</groupId>
<artifactId>SpringBatchExample</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>SpringBatchDemo</name>
<url>https://maven.apache.org</url>
<properties>
<jdk.version>1.8</jdk.version>
<spring.version>4.3.12.RELEASE</spring.version>
<spring.batch.version>3.0.8.RELEASE</spring.batch.version>
<mysql.driver.version>5.1.25</mysql.driver.version>
<junit.version>4.11</junit.version>
</properties>
<dependencies>
<!-- Spring Core -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- Spring jdbc, for database -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- Spring XML to/back object -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-oxm</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- MySQL database driver -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.driver.version}</version>
</dependency>
<!-- Spring Batch dependencies -->
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
<version>${spring.batch.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-infrastructure</artifactId>
<version>${spring.batch.version}</version>
</dependency>
<!-- Spring Batch unit test -->
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-test</artifactId>
<version>${spring.batch.version}</version>
</dependency>
<!-- Junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.thoughtworks.xstream</groupId>
<artifactId>xstream</artifactId>
<version>1.4.10</version>
</dependency>
</dependencies>
<build>
<finalName>spring-batch</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<version>2.9</version>
<configuration>
<downloadSources>true</downloadSources>
<downloadJavadocs>false</downloadJavadocs>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>${jdk.version}</source>
<target>${jdk.version}</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
批处理CSV输入文件的Spring批处理任务
这是我们用于Spring批处理的样本CSV文件的内容。
1001,Tom,Moody, 29/7/2013
1002,John,Parker, 30/7/2013
1003,Henry,Williams, 31/7/2013
Spring批处理作业配置
我们需要在配置文件中定义Spring Bean和Spring Batch作业。以下是job-batch-demo.xml文件的内容,这是Spring Batch项目最重要的部分。
<beans xmlns="https://www.springframework.org/schema/beans"
xmlns:batch="https://www.springframework.org/schema/batch" xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.springframework.org/schema/batch
https://www.springframework.org/schema/batch/spring-batch-3.0.xsd
https://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans-4.3.xsd
">
<import resource="../config/context.xml" />
<import resource="../config/database.xml" />
<bean id="report" class="com.Olivia.spring.model.Report"
scope="prototype" />
<bean id="itemProcessor" class="com.Olivia.spring.CustomItemProcessor" />
<batch:job id="DemoJobXMLWriter">
<batch:step id="step1">
<batch:tasklet>
<batch:chunk reader="csvFileItemReader" writer="xmlItemWriter"
processor="itemProcessor" commit-interval="10">
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>
<bean id="csvFileItemReader" class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="classpath:csv/input/report.csv" />
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<property name="names" value="id,firstname,lastname,dob" />
</bean>
</property>
<property name="fieldSetMapper">
<bean class="com.Olivia.spring.ReportFieldSetMapper" />
<!-- if no data type conversion, use BeanWrapperFieldSetMapper to map
by name <bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper">
<property name="prototypeBeanName" value="report" /> </bean> -->
</property>
</bean>
</property>
</bean>
<bean id="xmlItemWriter" class="org.springframework.batch.item.xml.StaxEventItemWriter">
<property name="resource" value="file:xml/outputs/report.xml" />
<property name="marshaller" ref="reportMarshaller" />
<property name="rootTagName" value="report" />
</bean>
<bean id="reportMarshaller" class="org.springframework.oxm.jaxb.Jaxb2Marshaller">
<property name="classesToBeBound">
<list>
<value>com.Olivia.spring.model.Report</value>
</list>
</property>
</bean>
</beans>
-
- 我们正在使用FlatFileItemReader来读取CSV文件,CustomItemProcessor来处理数据,并使用StaxEventItemWriter将数据写入XML文件。
-
- batch:job – 此标签定义我们要创建的作业。Id属性指定作业的ID。我们可以在单个xml文件中定义多个作业。
-
- batch:step – 此标签用于定义Spring Batch作业的不同步骤。
-
- Spring Batch框架提供了两种不同类型的处理方式,分别是“TaskletStep Oriented”和“Chunk Oriented”。在此示例中,选择了Chunk Oriented样式,它指的是逐个读取数据并创建将在事务边界内写出的“块”。
-
- reader: 用于读取数据的Spring bean。在此示例中,我们使用了csvFileItemReader bean,它是FlatFileItemReader的实例。
-
- processor: 用于处理数据的类。在此示例中,我们使用了CustomItemProcessor。
-
- writer: 用于将数据写入XML文件的bean。
-
- commit-interval: 此属性定义了一次处理完成后将提交的块的大小。基本上,它意味着ItemReader将逐个读取数据,ItemProcessor也将以相同的方式处理数据,但只有在与commit-interval的大小相等时,ItemWriter才会将数据写入。
- 作为此项目的一部分使用的三个重要接口是来自org.springframework.batch.item包的ItemReader、ItemProcessor和ItemWriter。
春季批处理模型类
这是文章《Spring批处理示例》的第4部分(共6部分)
首先,我们将CSV文件读取为Java对象,然后使用JAXB将其写入XML文件。以下是我们的模型类,其中包含必需的JAXB注解。
package com.Olivia.spring.model;
import java.util.Date;
import javax.xml.bind.annotation.XmlAttribute;
import javax.xml.bind.annotation.XmlElement;
import javax.xml.bind.annotation.XmlRootElement;
@XmlRootElement(name = "record")
public class Report {
private int id;
private String firstName;
private String lastName;
private Date dob;
@XmlAttribute(name = "id")
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
@XmlElement(name = "firstname")
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
@XmlElement(name = "lastname")
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
@XmlElement(name = "dob")
public Date getDob() {
return dob;
}
public void setDob(Date dob) {
this.dob = dob;
}
@Override
public String toString() {
return "Report [id=" + id + ", firstname=" + firstName + ", lastName=" + lastName + ", DateOfBirth=" + dob
+ "]";
}
}
请注意,模型类字段应与在Spring批处理映射配置中定义的字段相同,例如,在我们的情况下,属性名称为”names”的值为”id,firstname,lastname,dob”。
Spring批处理的FieldSetMapper
Spring批处理需要一个自定义的FieldSetMapper来转换日期。如果不需要数据类型转换,那么只需要使用BeanWrapperFieldSetMapper自动按名称映射值。扩展FieldSetMapper的Java类是ReportFieldSetMapper。
package com.Olivia.spring;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.validation.BindException;
import com.Olivia.spring.model.Report;
public class ReportFieldSetMapper implements FieldSetMapper<Report> {
private SimpleDateFormat dateFormat = new SimpleDateFormat("dd/MM/yyyy");
public Report mapFieldSet(FieldSet fieldSet) throws BindException {
Report report = new Report();
report.setId(fieldSet.readInt(0));
report.setFirstName(fieldSet.readString(1));
report.setLastName(fieldSet.readString(2));
// default format yyyy-MM-dd
// fieldSet.readDate(4);
String date = fieldSet.readString(3);
try {
report.setDob(dateFormat.parse(date));
} catch (ParseException e) {
e.printStackTrace();
}
return report;
}
}
Spring批处理ItemProcessor
根据工作配置的定义,itemProcessor将在itemWriter之前被触发。我们已经为此创建了一个CustomItemProcessor.java类。
package com.Olivia.spring;
import org.springframework.batch.item.ItemProcessor;
import com.Olivia.spring.model.Report;
public class CustomItemProcessor implements ItemProcessor<Report, Report> {
public Report process(Report item) throws Exception {
System.out.println("Processing..." + item);
String fname = item.getFirstName();
String lname = item.getLastName();
item.setFirstName(fname.toUpperCase());
item.setLastName(lname.toUpperCase());
return item;
}
}
我们可以在ItemProcessor的实现中操作数据,正如您所看到的,我将名字和姓氏的值转换为大写。
Spring配置文件
这是文章《Spring Batch示例》的第5部分(共6部分)。
在我们的Spring Batch配置文件中,我们导入了两个额外的配置文件 – context.xml 和 database.xml。
<beans xmlns="https://www.springframework.org/schema/beans"
xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
https://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans-4.3.xsd">
<!-- 将作业元数据存储在内存中 -->
<!--
<bean id="jobRepository"
class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean">
<property name="transactionManager" ref="transactionManager" />
</bean>
-->
<!-- 将作业元数据存储在数据库中 -->
<bean id="jobRepository"
class="org.springframework.batch.core.repository.support.JobRepositoryFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="transactionManager" ref="transactionManager" />
<property name="databaseType" value="mysql" />
</bean>
<bean id="transactionManager"
class="org.springframework.batch.support.transaction.ResourcelessTransactionManager" />
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>
</beans>
- jobRepository – JobRepository负责将每个Java对象存储到Spring Batch的正确元数据表中。
- transactionManager – 当提交间隔大小和处理的数据量相等时,它负责提交事务。
- jobLauncher – 这是Spring Batch的核心。该接口包含用于触发作业的run方法。
<beans xmlns="https://www.springframework.org/schema/beans"
xmlns:jdbc="https://www.springframework.org/schema/jdbc" xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans-4.3.xsd
https://www.springframework.org/schema/jdbc
https://www.springframework.org/schema/jdbc/spring-jdbc-4.3.xsd">
<!-- 连接到数据库 -->
<bean id="dataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/Test" />
<property name="username" value="test" />
<property name="password" value="test123" />
</bean>
<bean id="transactionManager"
class="org.springframework.batch.support.transaction.ResourcelessTransactionManager" />
<!-- 自动创建作业元数据表 -->
<!-- <jdbc:initialize-database data-source="dataSource"> <jdbc:script location="org/springframework/batch/core/schema-drop-mysql.sql"
/> <jdbc:script location="org/springframework/batch/core/schema-mysql.sql"
/> </jdbc:initialize-database> -->
</beans>
Spring Batch使用一些元数据表来存储批处理作业信息。我们可以从Spring Batch配置中创建这些表,但最好通过执行SQL文件手动创建,就像您在上面的注释代码中所看到的那样。从安全角度考虑,最好不要给Spring Batch数据库用户DDL执行权限。
Spring Batch表
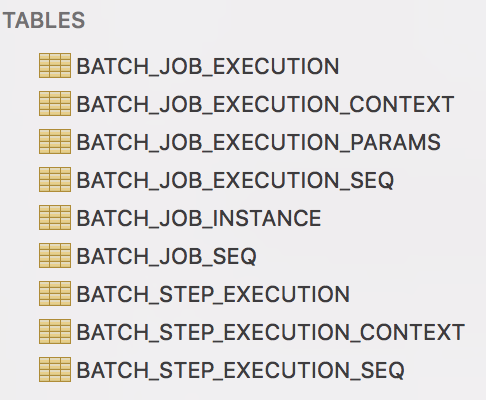
-
- 批量作业实例(Batch_job_instance)表保存与作业实例(JobInstance)相关的所有信息。
-
- 批量作业执行参数(Batch_job_execution_params)表保存与作业参数对象(JobParameters)相关的所有信息。
-
- 批量作业执行(Batch_job_execution)表保存与作业执行对象(JobExecution)相关的数据。每次运行作业时都会添加一行新数据。
-
- 批量步骤执行(Batch_step_execution)表保存与步骤执行对象(StepExecution)相关的所有信息。
-
- 批量作业执行上下文(Batch_job_execution_context)表保存与作业执行上下文(ExecutionContext)相关的数据。每个作业执行(JobExecution)都有一个作业执行上下文,其中包含了该作业执行所需的所有作业级别数据。这些数据通常表示在故障发生后必须检索的状态,以便作业实例可以从失败的地方重新启动。
-
- 批量步骤执行上下文(Batch_step_execution_context)表保存与步骤执行上下文(ExecutionContext)相关的数据。每个步骤执行(StepExecution)都有一个步骤执行上下文,其中包含需要为特定步骤执行持久化的所有数据。这些数据通常表示在故障发生后必须检索的状态,以便作业实例可以从失败的地方重新启动。
-
- 批量作业执行序列(Batch_job_execution_seq)表保存作业执行的数据序列。
-
- 批量步骤执行序列(Batch_step_execution_seq)表保存步骤执行的数据序列。
- 批量作业序列(Batch_job_seq)表保存作业的序列数据,以防我们有多个作业,将获得多行数据。
Spring Batch测试程序
这是文章《Spring Batch示例》的第6部分(共6部分)。
内容片段:我们的Spring Batch示例项目已经准备就绪,最后一步是编写一个测试类将其作为Java程序执行。
package com.Olivia.spring;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class App {
public static void main(String[] args) {
String[] springConfig = { "spring/batch/jobs/job-batch-demo.xml" };
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext(springConfig);
JobLauncher jobLauncher = (JobLauncher) context.getBean("jobLauncher");
Job job = (Job) context.getBean("DemoJobXMLWriter");
JobParameters jobParameters = new JobParametersBuilder().addLong("time", System.currentTimeMillis())
.toJobParameters();
try {
JobExecution execution = jobLauncher.run(job, jobParameters);
System.out.println("Exit Status : " + execution.getStatus());
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("Done");
context.close();
}
}
只需运行以上程序,您将获得以下类似的输出XML文件。
<?xml version="1.0" encoding="UTF-8"?><report><record id="1001"><dob>2013-07-29T00:00:00+05:30</dob><firstname>TOM</firstname><lastname>MOODY</lastname></record><record id="1002"><dob>2013-07-30T00:00:00+05:30</dob><firstname>JOHN</firstname><lastname>PARKER</lastname></record><record id="1003"><dob>2013-07-31T00:00:00+05:30</dob><firstname>HENRY</firstname><lastname>WILLIAMS</lastname></record></report>
这就是所有关于Spring Batch示例的内容,您可以从下面的链接下载最终项目。
下载Spring Batch示例项目
参考:官方指南

