Python Pandas教程:to_csv()导出DataFrame为CSV
Pandas DataFrame to_csv() 语法
DataFrame的to_csv()函数的语法是:
def to_csv(
self,
path_or_buf=None,
sep=",",
na_rep="",
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
mode="w",
encoding=None,
compression="infer",
quoting=None,
quotechar='"',
line_terminator=None,
chunksize=None,
date_format=None,
doublequote=True,
escapechar=None,
decimal=".",
)
一些重要的参数包括:
- path_or_buf: 用于写入CSV数据的文件对象。如果未提供此参数,CSV数据将以字符串形式返回。
- sep: CSV数据的分隔符。应该是长度为1的字符串,默认为逗号。
- na_rep: 表示空值或缺失值的字符串,默认为空字符串。
- columns: 指定要包含在CSV输出中的列的序列。
- header: 允许的值为布尔值或字符串列表,默认为True。如果为False,列名不会写入输出。如果是字符串列表,则用于写入列名。字符串列表的长度应与CSV文件中写入的列数相同。
- index: 如果为True,索引将包含在CSV数据中。如果为False,索引值不会写入CSV输出。
- index_label: 用于指定索引的列名。
将Pandas DataFrame保存为CSV文件的示例
让我们观察一些常见的例子,使用to_csv()函数将DataFrame转换为CSV数据。
将DataFrame转换为CSV字符串
import pandas as pd
d1 = {'Name': ['Pankaj', 'Meghna'], 'ID': [1, 2], 'Role': ['CEO', 'CTO']}
df = pd.DataFrame(d1)
print('DataFrame:\n', df)
# default CSV
csv_data = df.to_csv()
print('\nCSV String:\n', csv_data)
输出:
DataFrame:
Name ID Role
0 Pankaj 1 CEO
1 Meghna 2 CTO
CSV String:
,Name,ID,Role
0,Pankaj,1,CEO
1,Meghna,2,CTO
指定 CSV 输出的分隔符
csv_data = df.to_csv(sep='|')
print(csv_data)
输出:
|Name|ID|Role
0|Pankaj|1|CEO
1|Meghna|2|CTO
如果指定的分隔符长度不为1,则会引发TypeError: “分隔符”必须是一个字符的字符串。
选择仅导出CSV文件的几列数据
csv_data = df.to_csv(columns=['Name', 'ID'])
print(csv_data)
输出:
,Name,ID
0,Pankaj,1
1,Meghna,2
注意到索引不被视为有效的列。
忽略CSV输出中的标题行
csv_data = df.to_csv(header=False)
print(csv_data)
输出:
0,Pankaj,1,CEO
1,Meghna,2,CTO
在CSV中设置自定义列名
csv_data = df.to_csv(header=['NAME', 'ID', 'ROLE'])
print(csv_data)
输出:
,NAME,ID,ROLE
0,Pankaj,1,CEO
1,Meghna,2,CTO
再次强调,索引并不被视为DataFrame对象的列。
在CSV输出中跳过索引列
csv_data = df.to_csv(index=False)
print(csv_data)
输出:
Name,ID,Role
Pankaj,1,CEO
Meghna,2,CTO
在CSV文件中设置索引列的名称
csv_data = df.to_csv(index_label='Sl No.')
print(csv_data)
输出:
Sl No.,Name,ID,Role
0,Pankaj,1,CEO
1,Meghna,2,CTO
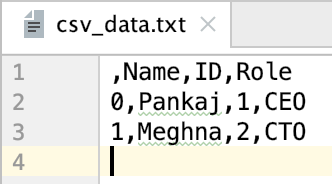
将DataFrame转换为CSV文件
with open('csv_data.txt', 'w') as csv_file:
df.to_csv(path_or_buf=csv_file)
在CSV输出中,Null、NA或Missing Data的表示方法
import pandas as pd
d1 = {'Name': ['Pankaj', 'Meghna'], 'ID': [1, pd.NaT], 'Role': [pd.NaT, 'CTO']}
df = pd.DataFrame(d1)
print('DataFrame:\n', df)
csv_data = df.to_csv()
print('\nCSV String:\n', csv_data)
csv_data = df.to_csv(na_rep="None")
print('带有空值表示的CSV字符串:\n', csv_data)
输出:
DataFrame:
Name ID Role
0 Pankaj 1 NaT
1 Meghna NaT CTO
CSV String:
,Name,ID,Role
0,Pankaj,1,
1,Meghna,,CTO
带有空值表示的CSV字符串:
,Name,ID,Role
0,Pankaj,1,None
1,Meghna,None,CTO
参考文献
- Pandas read_csv() – 将CSV文件读取为DataFrame
- Python Pandas模块教程
- DataFrame to_csv() API文档

