使用StandardScaler()函数对Python数据进行标准化
大家好,读者朋友们!在本文中,我们将专注于Python中最重要的预处理技术之一 – 使用StandardScaler()函数进行标准化。
那么,让我们开始吧!
对于标准化的需求
在进入标准化之前,让我们首先了解扩展的概念。
特征缩放是使用数据集建模算法的重要步骤。通常用于建模的数据是通过各种手段获得的。
- Questionnaire
- Surveys
- Research
- Scraping, etc.
因此,所获取的数据含有不同维度和尺度的特征。数据特征的不同尺度会对数据集的建模产生负面影响。
因为数据未经缩放,导致预测结果存在偏差,表现为错误分类率和准确率。因此,在建模之前有必要对数据进行缩放处理。
这就是标准化发挥作用的时候。
标准化是一种缩放技术,其将数据的统计分布转换为下面的格式,使数据与比例无关。
- mean – 0 (zero)
- standard deviation – 1
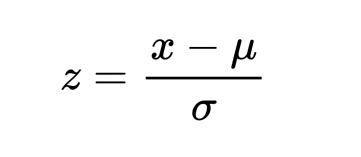
通过这样处理,整个数据集的均值为零,方差为单位。
让我们现在尝试在接下来的部分中实施标准化的概念。
Python sklearn StandardScaler() 函数可以被用来进行特征缩放。
Python的sklearn库为我们提供了StandardScaler()函数,用于将数据的值标准化为标准格式。
句法:用母语中文进行改写。只需要一种选项:
object = StandardScaler()
object.fit_transform(data)
根据以上语法,我们首先创建一个StandardScaler()函数的对象。进一步地,我们使用fit_transform()方法,并将分配的对象用于转换和标准化数据。
注意:标准化仅适用于遵循正态分布的数据值。
使用StandardScaler()函数对数据进行标准化。
来看一下下面的例子吧!
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
dataset = load_iris()
object= StandardScaler()
# Splitting the independent and dependent variables
i_data = dataset.data
response = dataset.target
# standardization
scale = object.fit_transform(i_data)
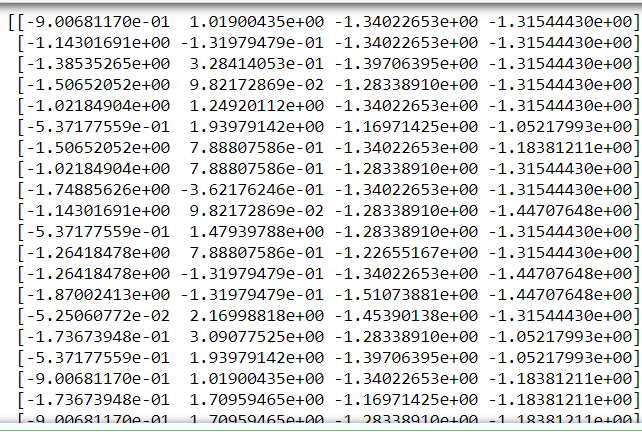
print(scale)
解释:
-
- 导入所需的库。我们已经导入了sklearn库以使用StandardScaler函数。
-
- 加载数据集。这里我们使用了sklearn.datasets库中的IRIS数据集。你可以在这里找到数据集。
-
- 设置一个对象到StandardScaler()函数。
-
- 按照上面所示,将自变量和目标变量分开。
- 使用fit_transform()函数将函数应用到数据集上。
结果:
结论
根据此,我们已经结束了本主题的讨论。如果你有任何问题,请随意在下方评论。
想要了解更多与Python相关的帖子,请关注 Python with JournalDev,并在此期间继续学习!祝您学习愉快! 🙂

