在R中进行异常值分析-检测和去除异常值
大家好,读者们!在这篇文章中,我们将详细讨论R编程中的异常值分析。
所以,让我们开始吧!!
数据中的异常值是什么?
在深入探讨异常值概念之前,让我们先专注于数据值的预处理。
在数据科学和机器学习领域,数据值的预处理是一个关键步骤。所谓预处理,是指在建模之前将所有的错误和噪音从数据中清除。
在我们的上一篇文章中,我们已经了解了在R编程中的缺失值分析。
今天,我们将集中讨论R中的同一个高级水平 – 异常值检测和去除。
异常值,顾名思义,是数据集中离其他数据点较远的数据点。也就是说,它们是与其他数据值相距较远,从而扰乱了数据集的整体分布。
这通常被认为是数据值的异常分布。
异常值对模型的影响
-
- 数据的格式发现出现了偏斜。
-
- 改变了数据的整体统计分布,包括均值、方差等。
- 导致模型的准确性水平出现偏差。
理解了异常值的影响之后,现在是时候着手实施了。
异常值分析 – 开始吧!
首先,我们非常重视在数据集中检测离群值的存在。
那么,让我们开始吧。我们使用了自行车租赁次数预测数据集。你可以在这里找到数据集!
1. 载入数据集
起初,我们使用read.csv()函数将数据集加载到R环境中。
在异常值检测之前,我们进行了缺失值分析,仅仅是为了检查是否存在任何NULL或缺失值。为此,我们使用了sum(is.na(data))函数。
#Removed all the existing objects
rm(list = ls())
#Setting the working directory
setwd("D:/Ediwsor_Project - Bike_Rental_Count/")
getwd()
#Load the dataset
bike_data = read.csv("day.csv",header=TRUE)
### Missing Value Analysis ###
sum(is.na(bike_data))
summary(is.na(bike_data))
#From the above result, it is clear that the dataset contains NO Missing Values.
这里的数据没有缺失值。
使用箱线图函数检测异常值。
说到这一点,现在是时候检测数据集中的异常值。为了达到这个目的,我们使用c()函数将数值数据列保存到一个单独的数据结构/变量中。
此外,我们使用了boxplot()函数来检测数值变量中是否存在异常值。
盒须图 (Hé Xū Tú)
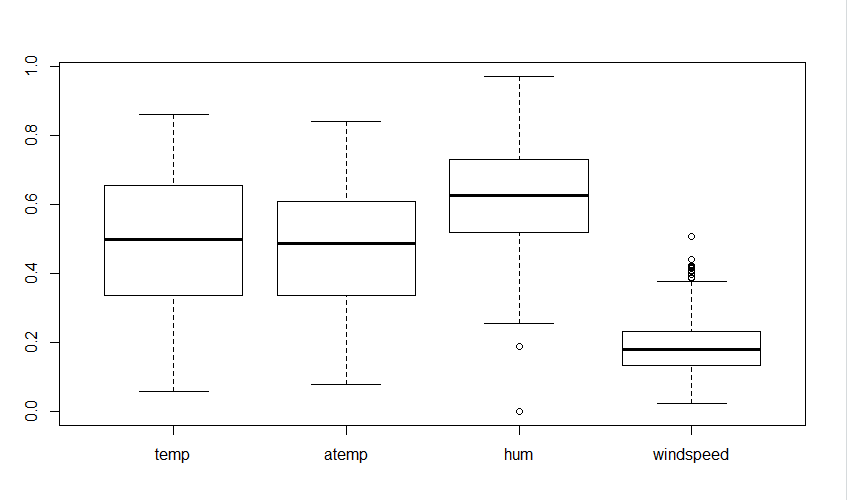
从图表可见,变量’hum’和’windspeed’的数据值中明显存在异常值。
3. 用NULL值替换离群值
现在,在使用R进行异常值分析之后,我们将通过boxplot()方法识别出的异常值替换为NULL值,以便像下面所示对其进行处理。
##############################Outlier Analysis -- DETECTION###########################
# 1. Outliers in the data values exists only in continuous/numeric form of data variables. Thus, we need to store all the numeric and categorical independent variables into a separate array structure.
col = c('temp','cnt','hum','windspeed')
categorical_col = c("season","yr","mnth","holiday","weekday","workingday","weathersit")
# 2. Using BoxPlot to detect the presence of outliers in the numeric/continuous data columns.
boxplot(bike_data[,c('temp','atemp','hum','windspeed')])
# From the above visualization, it is clear that the data variables 'hum' and 'windspeed' contains outliers in the data values.
#OUTLIER ANALYSIS -- Removal of Outliers
# 1. From the boxplot, we have identified the presence of outliers. That is, the data values that are present above the upper quartile and below the lower quartile can be considered as the outlier data values.
# 2. Now, we will replace the outlier data values with NULL.
for (x in c('hum','windspeed'))
{
value = bike_data[,x][bike_data[,x] %in% boxplot.stats(bike_data[,x])$out]
bike_data[,x][bike_data[,x] %in% value] = NA
}
#Checking whether the outliers in the above defined columns are replaced by NULL or not
sum(is.na(bike_data$hum))
sum(is.na(bike_data$windspeed))
as.data.frame(colSums(is.na(bike_data)))
4. 确认所有异常值已被替换为NULL
现在,我们使用sum(is.na())函数检查缺失数据的存在,即异常值是否已正确转换为缺失值。
输出:
> sum(is.na(bike_data$hum))
[1] 2
> sum(is.na(bike_data$windspeed))
[1] 13
> as.data.frame(colSums(is.na(bike_data)))
colSums(is.na(bike_data))
instant 0
dteday 0
season 0
yr 0
mnth 0
holiday 0
weekday 0
workingday 0
weathersit 0
temp 0
atemp 0
hum 2
windspeed 13
casual 0
registered 0
cnt 0
因此,我们将“嗡嗡声”列中的2个异常点和“风速”列中的13个异常点转换为缺失值(NA)。
5. 丢弃具有缺失值的列
最后,我们使用‘tidyr’库中的drop_na()函数删除缺失值,处理缺失值。
#Removing the null values
library(tidyr)
bike_data = drop_na(bike_data)
as.data.frame(colSums(is.na(bike_data)))
输出结果:
因此,现在所有的异常值都已被有效去除!
> as.data.frame(colSums(is.na(bike_data)))
colSums(is.na(bike_data))
instant 0
dteday 0
season 0
yr 0
mnth 0
holiday 0
weekday 0
workingday 0
weathersit 0
temp 0
atemp 0
hum 0
windspeed 0
casual 0
registered 0
cnt 0
结论
通过这个,我们已经达到了这个话题的结束。如果你遇到任何问题,请随时在下面发表评论。要获取更多与R编程相关的帖子,请继续关注!
直到那时,祝你学习愉快!:)

