在R编程中的unique()函数
R中的unique()函数用于消除向量、数据框或矩阵中重复的值或行。
在探索性数据分析(EDA)中,unique()函数因为可以直接识别和删除数据中的重复值而显得很重要。
在本文中,我们将揭示R编程中unique()函数的各种应用。让我们开始吧!
获得独特值的概念
好的,在进入这个话题之前,了解其中背后的理念是很重要的。在这种情况下,那就是唯一值。唯一函数通过消除重复计数来返回唯一值。
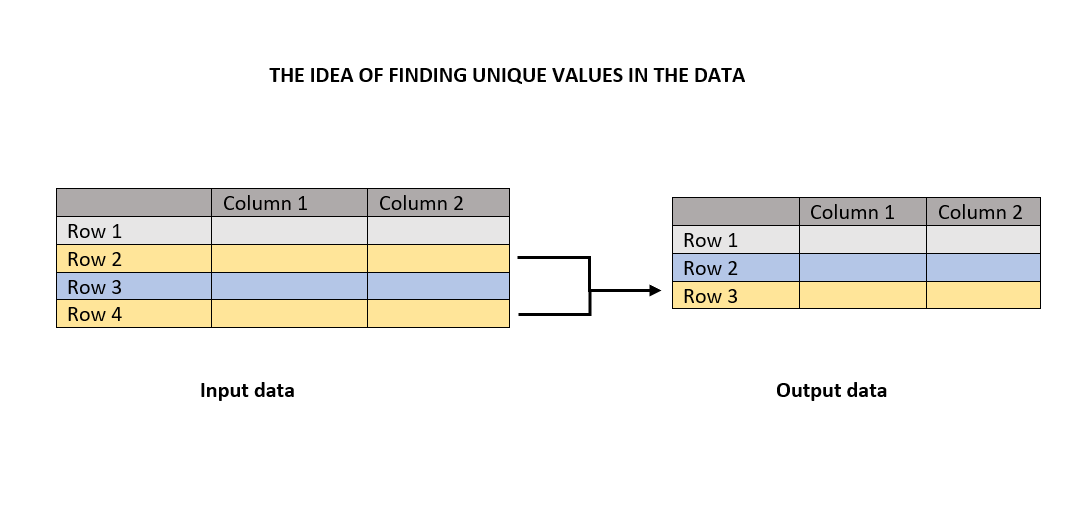
图表告诉你,唯一函数将查找重复值并消除它们,以返回唯一值。在接下来的部分中将有许多插图向你展示一些很有价值的内容。
R中Unique()函数的语法
独特:unique()函数用于识别和消除数据中存在的重复计算。
unique(x)
在哪里
X可以是一个向量、一个数据框或一个矩阵。
R中unique()函数的一个简单示例
如果你有一个包含重复值的向量,那么借助于unique()函数,你可以轻松地使用一行代码消除这些重复值。
让我们看看它是如何工作的… tā shì de…)
#An input vector having duplicate values
df<-c(1,2,3,2,4,5,1,6,8,9,8,6)
#elimnates the duplicate values in the vector
unique(df)
Output = 1 2 3 4 5 6 8 9
在上面的例子中,你可以观察到输入向量中有很多重复的值。
在将该向量传递给唯一函数后,它会消除所有重复的值并仅返回唯一的值,如上所示。
在一个矩阵中找到唯一的值。
现在,我们要找出矩阵中存在的重复值,并使用unique函数将其剔除。
为了实现这一点,我们首先需要创建一个由重复值组成的 n 行 n 列的矩阵。
要创建一个矩阵,请运行以下代码。
#creates a 6 x 4 matrix having 24 elements
df<-matrix(rep(1:20,length.out=24),nrow = 6,ncol=4,byrow = T)
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
[4,] 13 14 15 16
[5,] 17 18 19 20
[6,] 1 2 3 4
你可以很容易地注意到,最后一行完全是重复的。你只需要使用 unique() 函数来消除这些重复值。
#removes the duplicate values
unique(df)
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
[4,] 13 14 15 16
[5,] 17 18 19 20
呀呀!
你做到了!使用唯一功能,去除了矩阵中的所有重复值,并返回一个只包含唯一值的矩阵。
在数据框中找出独特的值。
迄今为止,我们通过消除重复计数来提取独特值,主要是对向量和矩阵进行操作。
在这个部分,让我们专注于获取数据框中存在的唯一值。
运行以下代码来创建一个数据框架。
#creates a data frame
> Class_data<-data.frame(Student=c('Naman','Megh','Mark','Naman','Megh','Mark'),Age=c(22,23,24,22,23,24),Gender=c('Male','Female','Male','Male','Female','Male'))
#dataframe
Class_data
Student Age Gender
1 Naman 22 Male
2 Megh 23 Female
3 Mark 24 Male
4 Naman 22 Male
5 Megh 23 Female
6 Mark 24 Male
这是数据框架,上面显示了重复计数。让我们应用唯一函数以去除这里的重复值。
unique(Class_data)
Student Age Gender
1 Naman 22 Male
2 Megh 23 Female
3 Mark 24 Male
哇!这个独特的功能通过消除重复值,返回了数据框中所有唯一的值。
就像这样,在R中使用unique()函数,你可以轻松获取数据中的唯一值。
找出特定列的唯一值
如果需要从特定的列而不是数据集中获取唯一的值,你该怎么办?
不必担心,使用unique()函数,我们也可以按照下面的方式获取特定列的唯一值。
#creates a data frame
> Class_data<-data.frame(Student=c('Naman','Megh','Mark','Naman','Megh','Mark'),Age=c(22,23,24,22,23,24),Gender=c('Male','Female','Male','Male','Female','Male'))
#dataframe
Class_data
Student Age Gender
1 Naman 22 Male
2 Megh 23 Female
3 Mark 24 Male
4 Naman 22 Male
5 Megh 23 Female
6 Mark 24 Male
好的,我将使用我们在前面章节中使用的相同数据框来方便理解。
让我们使用唯一函数来排除重复值。 yī shù zhí.)
unique(Class_data$Student)
Output = "Naman" "Megh" "Mark"
同样地,我们也可以获取年龄或性别列中的唯一值。
unique(Class_data$Gender)
"Male" "Female"
找出唯一值的长度
在这一部分中,我们将获取数据中唯一值的计数。这个应用程序对于更好地了解您的数据并使其准备好进一步分析非常有用。
#importing the dataset
datasets::BOD
Time demand
1 1 8.3
2 2 10.3
3 3 19.0
4 4 16.0
5 5 15.6
6 7 19.8
好的,我们在这里使用BOD数据集。先找出唯一值,然后再计算个数。
#returns the unique value
unique(BOD$demand)
Output = 8.3 10.3 19.0 16.0 15.6 19.8
好的,现在我们在BOD数据集的需求列中有独特的值。
现在,我们可以开始找到唯一值的数量了。
#returns the length of unique values
length(unique(BOD$demand))
Output = 6
总结
嗯,R中的unique()函数是进行探索性数据分析(EDA)时非常重要的一个函数。
它帮助你更好地理解你的数据,并提供特定的计数。
这篇文章向你介绍了unique()函数的多种应用和用例。愿你分析工作开心!

