Python解析CSV文件的完全指南:从基础到高级技巧
CSV文件在存储表格数据方面被广泛使用。我们可以将数据库表格或Excel文件中的数据轻松导出为CSV文件。它不仅易于人类阅读,也易于程序处理。在本教程中,我们将学习如何在Python中解析CSV文件。
什么是解析?
解析文件意味着从文件中读取数据。该文件可以包含文本数据,也可以是电子表格。
什么是CSV文件?
CSV代表逗号分隔值文件,即数据之间使用逗号进行分隔。CSV文件是由处理大量数据的程序创建的。CSV文件中的数据可以很容易地导出为电子表格和数据库形式,并且可以导入到其他程序中使用。让我们看看如何解析CSV文件。在Python中解析CSV文件非常简单。Python有一个内置的CSV库,提供了从CSV文件读取和写入数据的功能。该库支持各种格式的CSV文件,使数据处理更加用户友好。
使用Python解析CSV文件
使用内置的Python CSV模块读取CSV文件。
import csv
with open('university_records.csv', 'r') as csv_file:
reader = csv.reader(csv_file)
for row in reader:
print(row)输出:
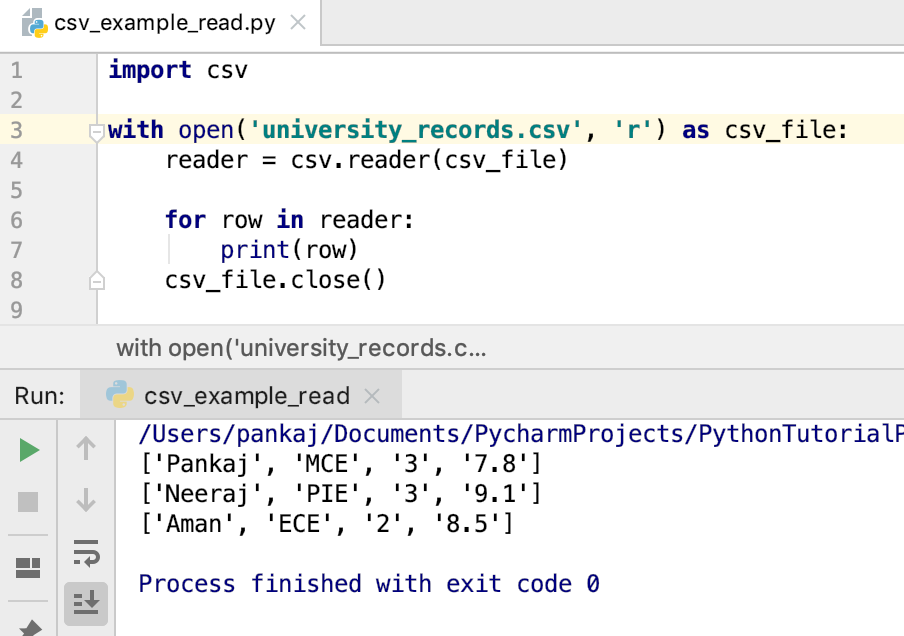
用Python编写一个CSV文件
对于写入文件,我们必须以写入模式或追加模式打开它。在这里,我们将把数据追加到现有的CSV文件中。
import csv
row = ['David', 'MCE', '3', '7.8']
row1 = ['Lisa', 'PIE', '3', '9.1']
row2 = ['Raymond', 'ECE', '2', '8.5']
with open('university_records.csv', 'a') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(row)
writer.writerow(row1)
writer.writerow(row2)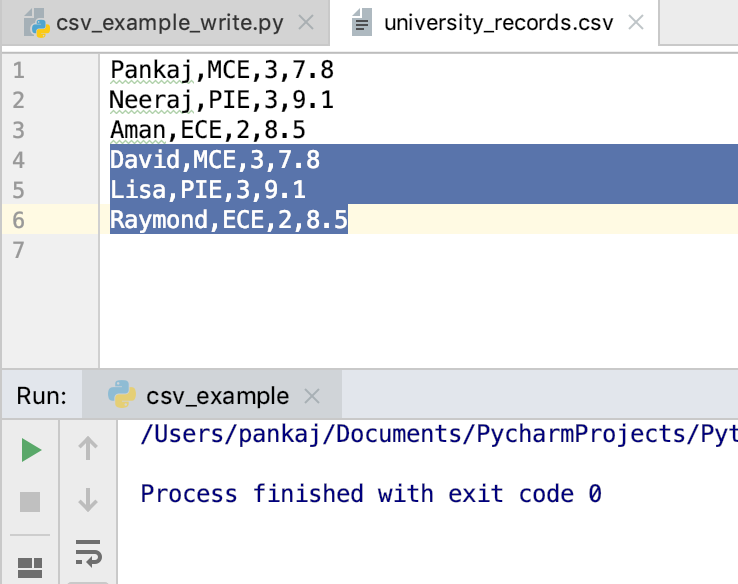
使用Pandas库解析CSV文件
还有一种处理CSV文件的方法,这也是最流行且更专业的方法,那就是使用pandas库。Pandas是一个Python数据分析库,它提供了不同的结构、工具和操作,用于处理和操纵给定数据,其中大多数是二维或一维表格。
pandas库的使用和特点
- 数据集透视和重塑
- 使用DataFrame对象进行索引的数据操作
- 数据过滤
- 数据集的合并和连接操作
- 大规模数据集的切片、索引和子集
- 缺失数据处理和数据对齐
- 行/列插入和删除
- 不同文件格式的一维数据处理
- 各种文件格式数据的读写工具
要使用CSV文件,您需要安装pandas。通过以下步骤使用PIP安装它非常简单。
$ pip install pandas
一旦安装完成,你可以开始使用了。
使用Pandas模块读取CSV文件
在使用pandas导入CSV文件之前,您需要知道您的数据文件在文件系统中的路径以及您当前的工作目录。我建议将您的代码和数据文件放在同一个目录或文件夹中,这样您就不需要指定路径,从而节省时间和空间。
import pandas
result = pandas.read_csv('ign.csv')
print(result)输出:
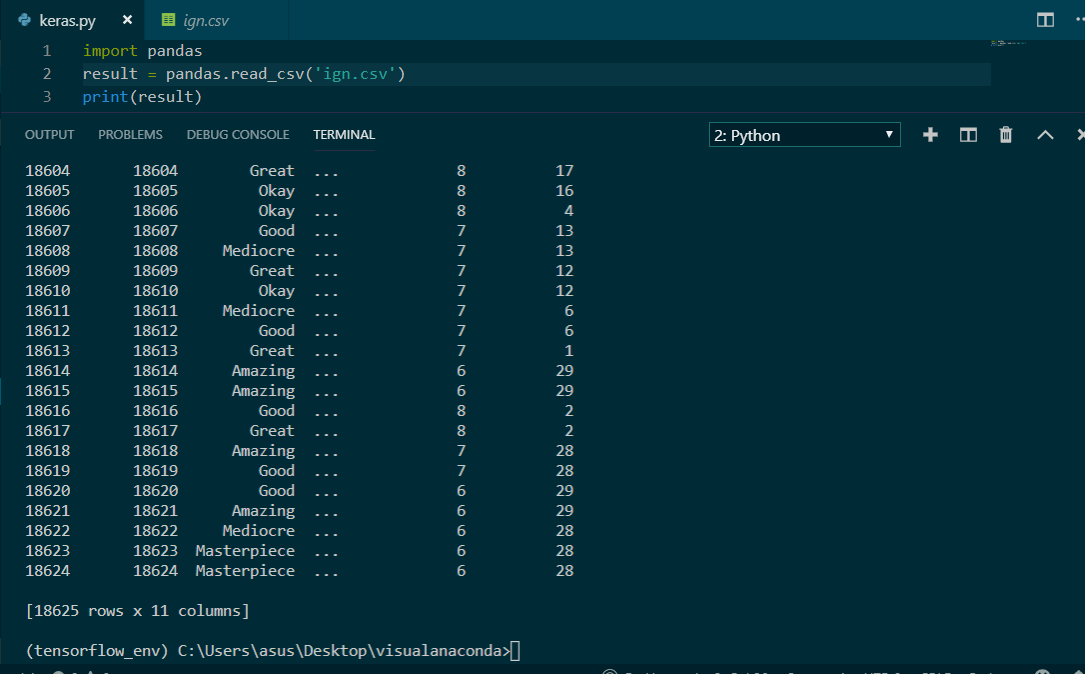
使用Pandas模块编写CSV文件
使用pandas编写CSV文件与读取一样简单。唯一的新术语是DataFrame。Pandas的DataFrame是一个二维的、异构的表格数据结构(数据按照行和列的表格方式排列)。Pandas的DataFrame由三个主要组成部分组成 – 数据、列和行 – 并带有标记的x轴和y轴(行和列)。
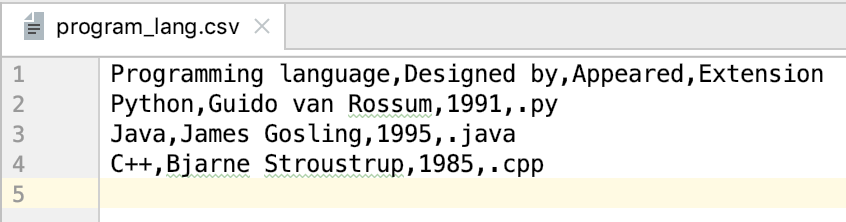
from pandas import DataFrame
C = {'编程语言': ['Python', 'Java', 'C++'],
'设计者': ['Guido van Rossum', 'James Gosling', 'Bjarne Stroustrup'],
'出现年份': ['1991', '1995', '1985'],
'扩展名': ['.py', '.java', '.cpp'],
}
df = DataFrame(C, columns=['编程语言', '设计者', '出现年份', '扩展名'])
export_csv = df.to_csv(r'program_lang.csv', index=None, header=True)输出:
结论
我们学习了如何使用内置的CSV模块和pandas模块解析CSV文件。解析文件有许多不同的方法,但是程序员们并不广泛使用它们。像PlyPlus、PLY和ANTLR这样的库是用于解析文本数据的一些库。现在你知道如何使用内置的CSV库和强大的pandas模块来读写CSV格式的数据了。上面展示的代码非常基础和直接。对于熟悉Python的人来说,它是可理解的,所以我认为没有必要解释。然而,处理包含空白和模棱两可的复杂数据并不容易。这需要实践和对pandas中各种工具的了解。CSV是保存和共享数据的最佳方式。Pandas是CSV模块的一个很好的替代品。一开始可能会感到困难,但学会它并不难。稍微练习一下,你就能掌握它。

